Тестирование Linux на DROP сетевых пакетов. Разные методы и их эффективность. Тесты синтетические, но от этого не становятся менее интересными. Пример от Cloudflare.
Тестирование Linux на DROP сетевых пакетов. Разные методы и их эффективность. Тесты синтетические, но от этого не становятся менее интересными. Пример от Cloudflare.
Для иллюстрации производительности методов будут продемонстрированы некоторые цифры. Тесты синтетические, т.е. не на реальной сети с реальными пользователями и трафиком, так что не воспринимайте цифры слишком серьезно. Будет использоваться один из Intel серверов c 10Gbps сетевым интерфейсом. Детали железа не особо важны, т.к. тесты будут показывать вопросы, связанные с операционкой, а не с ограничениями по железу.
Что происходит при тестировании:
- передача большого количества мелких UDP пакетов, достигая уровня в 14Mpps
- этот трафик направляется на единственный CPU на сервере
- измеряется количество пакетов, обработанных ядром на этом CPU
Мы не пытаемся максимизировать ни скорость приложения в юзерспейсе (userspace), ни количество пакетов. Вместо этого мы пытаемся показать узкие места самого ядра.
Синтетический трафик пытается максимально нагрузить conntrack - используется рандомный IP адрес источника и порт. Tcpducmp будет выглядеть примерно следующим образом:
$ tcpdump -ni vlan100 -c 10 -t udp and dst port 1234
IP 198.18.40.55.32059 > 198.18.0.12.1234: UDP, length 16
IP 198.18.51.16.30852 > 198.18.0.12.1234: UDP, length 16
IP 198.18.35.51.61823 > 198.18.0.12.1234: UDP, length 16
IP 198.18.44.42.30344 > 198.18.0.12.1234: UDP, length 16
IP 198.18.106.227.38592 > 198.18.0.12.1234: UDP, length 16
IP 198.18.48.67.19533 > 198.18.0.12.1234: UDP, length 16
IP 198.18.49.38.40566 > 198.18.0.12.1234: UDP, length 16
IP 198.18.50.73.22989 > 198.18.0.12.1234: UDP, length 16
IP 198.18.43.204.37895 > 198.18.0.12.1234: UDP, length 16
IP 198.18.104.128.1543 > 198.18.0.12.1234: UDP, length 16
На другой стороне все пакеты будут направлены на одну очередь прерываний (RX), т.е. на один CPU. Делается это через ethtool:
ethtool -N ext0 flow-type udp4 dst-ip 198.18.0.12 dst-port 1234 action 2
Оценочное тестирование всегда довольно сложное. Когда мы готовили тесты, мы обнаружили, что любые активные сырые сокеты (raw socket) сильно влияют на производительность. Это вполне очевидно, но легко не учесть. Перед тестами убедитесь, что у вас не запущен, к примеру, tcpdump.
$ ss -A raw,packet_raw -l -p|cat
Netid State Recv-Q Send-Q Local Address<img border="0" src="/static/img/smilies/tongue.gif" alt="tongue.gif" />ort
p_raw UNCONN 525157 0 *:vlan100 users<img border="0" src="/static/img/smilies/sad.gif" alt="sad.gif" />("tcpdump",pid=23683,fd=3))
В конце концов мы отключили Intel Turbo Boost:
echo 1 | sudo tee /sys/devices/system/cpu/intel_pstate/no_turbo
Это классная функция, и увеличивает производительность по крайней мере на 20%, но она также очень сильно влияет на разброс показаний при замерах. Со включенным бустом разброс достигал +-1.5%. С выключенным - 0.25%.
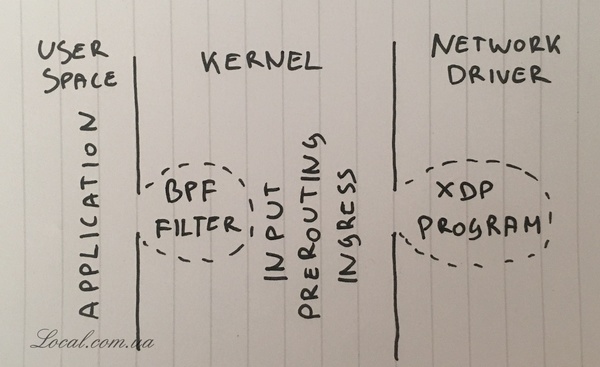 1. Отброс/DROP пакетов в приложении
1. Отброс/DROP пакетов в приложении
Начинаем с доставки пакетов к приложению и отбрасывании их уже с помощью него. Чтобы убедиться, что файервол не влияет на это делаем так:
iptables -I PREROUTING -t mangle -d 198.18.0.12 -p udp --dport 1234 -j ACCEPT
iptables -I PREROUTING -t raw -d 198.18.0.12 -p udp --dport 1234 -j ACCEPT
iptables -I INPUT -t filter -d 198.18.0.12 -p udp --dport 1234 -j ACCEPT
Код приложения - обычный цикл, который получает данные и сразу же их отбрасывает (в юзерспейсе):
s = socket.socket(AF_INET, SOCK_DGRAM)
s.bind(("0.0.0.0", 1234))
while True:
s.recvmmsg([...])
Код приложения:
https://github.com/cloudflare/cloudflare-blog/blob/master/2018-07-dropping-packets/recvmmsg-loop.c
$ ./dropping-packets/recvmmsg-loop
packets=171261 bytes=1940176
Тут мы получаем жалкие 175kpps:
$ mmwatch 'ethtool -S ext0|grep rx_2'
rx2_packets: 174.0k/s
Железо нам дает 14Mpps, но мы не можем обработать это ядром на одном CPU с одной очередью прерываний. mpstat это подтверждает:
$ watch 'mpstat -u -I SUM -P ALL 1 1|egrep -v Aver'
01:32:05 PM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
01:32:06 PM 0 0.00 0.00 0.00 2.94 0.00 3.92 0.00 0.00 0.00 93.14
01:32:06 PM 1 2.17 0.00 27.17 0.00 0.00 0.00 0.00 0.00 0.00 70.65
01:32:06 PM 2 0.00 0.00 0.00 0.00 0.00 100.00 0.00 0.00 0.00 0.00
01:32:06 PM 3 0.95 0.00 1.90 0.95 0.00 3.81 0.00 0.00 0.00 92.38
Как видите, код приложения не является узким местом, используя 27% системы + 2% юзерспейса на CPU #1, в то время как SOFTIRQ на CPU #2 сжирает 100% ресурсов.
Кстати, использовать recvmmsg(2) довольно важно в наши пост-Спектровые дни (Spectre + Meltdown все же помнят?). Системные вызовы теперь требуют больше ресурсов. Мы используем ядро 4.14 с KPTI и retpolines:
$ tail -n +1 /sys/devices/system/cpu/vulnerabilities/*
==> /sys/devices/system/cpu/vulnerabilities/meltdown /sys/devices/system/cpu/vulnerabilities/spectre_v1 /sys/devices/system/cpu/vulnerabilities/spectre_v2 protocol == IPPROTO_UDP
&& (htonl(iph->daddr) & 0xFFFFFF00) == 0xC6120000 // 198.18.0.0/24
&& udph->dest == htons(1234)) {
return XDP_DROP;
}
}
XDP программа должна быть скомпилирована современным clang, который умеет делать BPF байткод. После этого загружаем и проверяем XDP программу:
$ ip link show dev ext0
4: ext0: mtu 1500 xdp qdisc fq state UP mode DEFAULT group default qlen 1000
link/ether 24:8a:07:8a:59:8e brd ff:ff:ff:ff:ff:ff
prog/xdp id 5 tag aedc195cc0471f51 jited
И смотрим цифры в статистике интерфейса (ethtool -S)
$ mmwatch 'ethtool -S ext0|egrep "rx"|egrep -v ": 0"|egrep -v "cache|csum"'
rx_out_of_buffer: 4.4m/s
rx_xdp_drop: 10.1m/s
rx2_xdp_drop: 10.1m/s
Итого получаем 10Mpps на одном CPU.


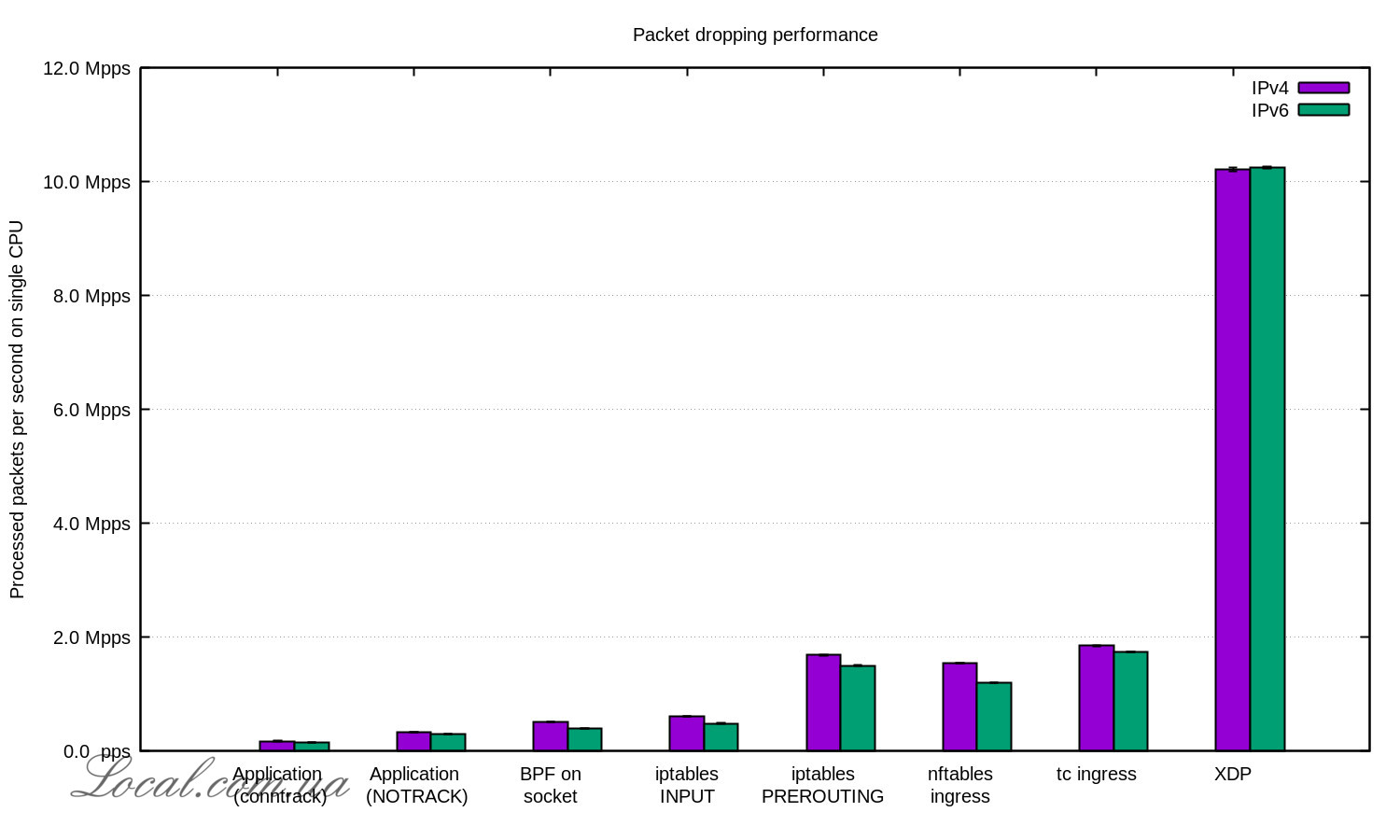
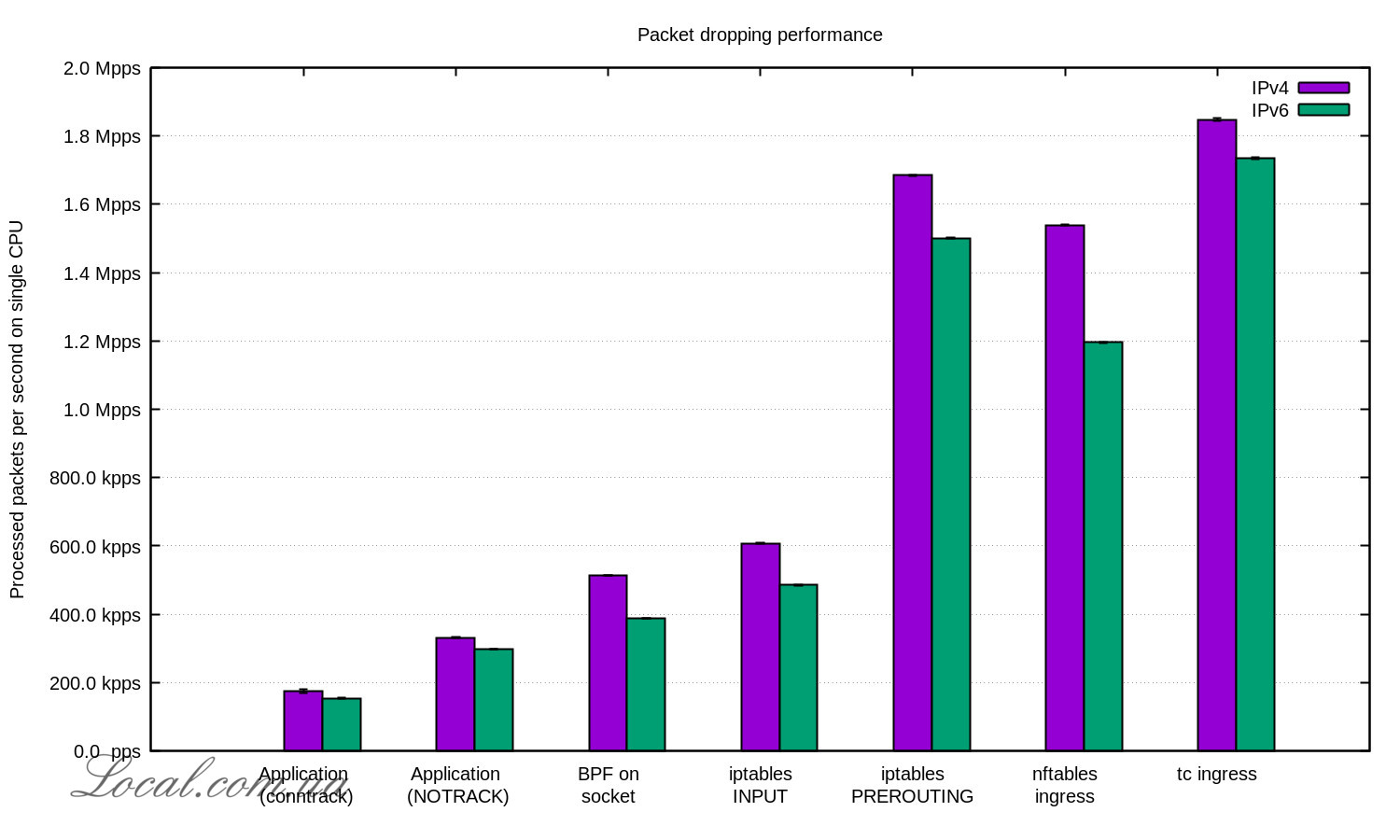
Последнее это уже не CPU, но идея хорошая
Вот уж опять маркетологи какие-то, nftables чуть медленнее, но "В любом случае nftables рулит" - это что ещё за бред и странный пассаж? Вот прям рекламный буклет перед глазами - наши фрукты ещё не дозрели, но всё-равно они лучшие. Зачем эти мантры в технической статье? Хорошо ещё, что при переводе смайлик убрали из оригинальной статьи.
Как это не CPU? То, что они изменили контекст и теперь BPF работает не в workers, а в ksoftirqd потоках даёт выигрыш при нормальном affinity и NAPI, но эти потоки всё также отрабатываются на CPU. А вот когда irqchip ограничен effective_affinity и нет NAPI, наступает северный пушной зверёк, т.к. все прерывания будут отрабатыватся на ограниченном количестве ядер (как правило, effective_affinity, если ограничен, то effective_affinity_list установлен в 1, то есть irqchip не умеет роутить/распределять прерывания на разные ядра), как пример - их первый тест, и 175kpps это ещё очень хороший результат, видимо, проц достаточно мощный. А вот проблема, о которой я пишу - типична для ARM'ов. Привет, новые тенденциозные ARM-сервера и маршрутизаторы.
https://github.com/LTD-Beget/syncookied актуальная тема
habr.com/...1892/
Вы должны войти