Google, AMD, Xilinx, Micron и Mellanox объединили силы с IBM в деле создания новой согласованной высокопроизводительной шины, которая получила имя Open Coherent Accelerator Processor Interface (OpenCAPI). Одна линия интерфейса обеспечивает скорость передачи данных до 25 Гбит/с. Для сравнения: спецификации PCIe 3.0 обеспечивают максимальную скорость на одну линию до 8 Гбит/с.
Google, AMD, Xilinx, Micron и Mellanox объединили силы с IBM в деле создания новой согласованной высокопроизводительной шины, которая получила имя Open Coherent Accelerator Processor Interface (OpenCAPI). Одна линия интерфейса обеспечивает скорость передачи данных до 25 Гбит/с. Для сравнения: спецификации PCIe 3.0 обеспечивают максимальную скорость на одну линию до 8 Гбит/с.
Возможно, кто-то помнит, как 10 лет назад AMD представила технологию Torrenza. В её основе лежала идея создания быстрого и согласованного интерфейса между CPU и различными типами ускорителей (через Hyper Transport). Это была одна из первых инициатив в деле продвижения гетерогенных вычислений.
Сегодня уже существует немало практических воплощений концепции гетерогенных вычислений — наиболее популярная предполагает ускорение высокопараллельных расчётов общего назначения при помощи GPU. Есть ускорители шифрования, сжатия, сети, но преимущества таких решений порой нивелируются необходимостью передавать данные центральному процессору и обратно, в результате чего порой куда эффективнее переложить нагрузку на CPU, добавив дополнительные инструкции.
Но сегодня времена меняются: сенсоры Интернета вещей, семантические веб-службы и обычные веб-сайты создают огромные экспоненциально растущие объёмы данных, которые не могут храниться и анализироваться обычным способом. В результате всё активнее применяется машинное обучение и анализ больших данных: всё это требует существенно большего объёма вычислений. Закон Мура в ближайшие годы полностью остановится, так что от новых техпроцессов не приходится ждать принципиальных улучшений. Вычислительные ресурсы обеспечат чипы ASIC (как в случае Google TPU), FPGA (как в проекте Microsoft Catapult) и GPU.
Все подобные ускорители нуждаются в технологии вроде Torrenza, но нового поколения — универсального скоростного и согласованного интерфейса связи с CPU. NVIDIA представила собственную такую технологию NVLink, но рынку нужен открытый стандарт, и IBM собирается поделиться своим интерфейсом CAPI с другими.
Чтобы развить это начинание, Google, AMD, Xilinx, Micron и Mellanox объединили силы с IBM в деле создания новой согласованной высокопроизводительной шины, которая получила имя Open Coherent Accelerator Processor Interface (OpenCAPI). Одна линия интерфейса обеспечивает скорость передачи данных до 25 Гбит/с. Для сравнения: спецификации PCIe 3.0 обеспечивают максимальную скорость на одну линию до 8 Гбит/с.
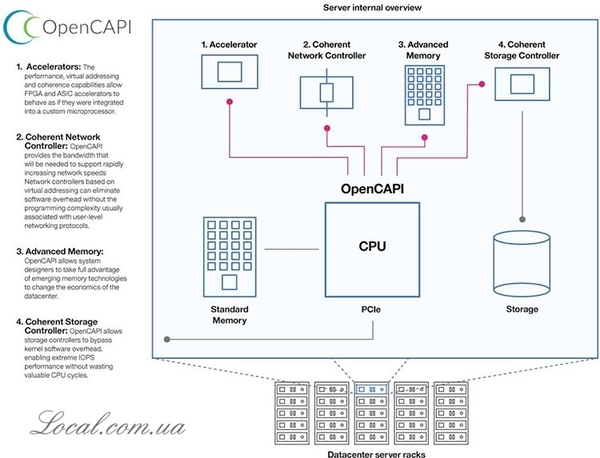
Уже в 2017 году интерфейс OpenCAPI появится в серверах IBM POWER9, которые, таким образом, будут поддерживать не только скоростной интерфейс для NVIDIA GPU (через NVLink), но также обеспечит более эффективную работу ускорителей Google ASIC и Xilinx FPGA. AMD тоже получит доступ к альтернативе NVLink для связи ускорителей Radeon с серверными процессорами Zen. Micron сможет подключать к CPU более скоростную память. Mellanox сможет сделать то же с сетевыми ускорителями. OpenCAPI также делает чипы FPGA привлекательными для существенно более широкого спектра приложений. Выигрывают все, кроме Intel.
К слову, Dell/EMC присоединилась к альянсу несколько дней назад, а NVIDIA является членом консорциума OpenCAPI на уровне вкладчика (как Xilinx и HP Enterprise). Интерфейс OpenCAPI может оказать существенное влияние на серверный рынок — возможно, это самый крупный анонс в секторе серверов в этом году.




следуя логике, следом за этим интерфейсом появятся 4-х портовые 10Г карты, и 2-х портовые 40Г
Это бы хорошо, только переварит ли столько процессор, тут хотябы 2-х портовая 10Г карта обрабатывала количество нужного трафика, чтобы можно было отказаться от аппаратных маршрутизаторов. Тут если бы еще и софт под такие скорости был. Хотя может за шиной и софт напишут.
А там часто 1:1000 с универсальным процессором, в пользу спецпроцессора.
Аппаратная реализация, это не переваривание загружаемой программы.
А в чем проблема сейчас маршрутизировать 10G сквозного трафика?
Ви маєте увійти під своїм обліковим записом