Melanxolik
-
Всього повідомлень
678 -
Приєднався
-
Останній візит
-
Дней в лидерах
3
Тип контенту
Профили
Форум
Календарь
Все, що було написано Melanxolik
-
нет, изменения только по российскому направлению.

-
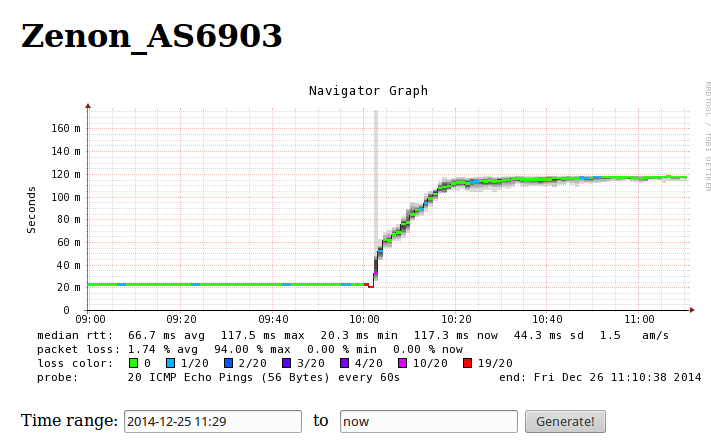
К сожалению вижу по мониторингу с 10 утра изменились пинги на гугл, контакт, фишки, с 20мс выросло до 120.
-

НУЖЕН СОВЕТ: Сетевая карта для сервака!
тема ответил в Archy_k пользователя Melanxolik в Для тих, хто в пелюшках ще
? тут фишка в том что это не выделенный NAS, а все в одном флаконе, внешний трафик по идее ведь тогда должен балансироваться, даже если внутренний будет по одному ядру ходить. Ну и также, а вдруг рост? вруг доступ уйдет на отдельный таз, а этот останется как роутер. -
Интернет МИКС: МИР + Украина = сколько чего конкретно?
тема ответил в Archy_k пользователя Melanxolik в Для тих, хто в пелюшках ще
проблема не в трансах, а в сетевом которое молотит, там просто полка по железке и её надо махнуть для начала. -
HP PROLIANT DL380 G6 загрузка ядра
тема ответил в morfey пользователя Melanxolik в Цілісність системи
на роутерах как раз HT надо выключать, полезностей он не дает. -
HP PROLIANT DL380 G6 загрузка ядра
тема ответил в morfey пользователя Melanxolik в Цілісність системи
del скачивайте результат через download. дофига текста. -
http://www.hyper-v-mart.com/HowTo/Configure_HyperV_Virtual_Network.aspx процедура особо не отличается. суть в том что с помощью менеджера hyper-v вы создаете виртуальный адаптер который входит в бридж. только ваш адрес на виртуальном адаптере запишите если статика, так как может слететь при конфигурировании.
-
Можно на земле попробовать другую антенну А в обще действительно, попробуйте ниже частоты чем 2.4
-
Интернет МИКС: МИР + Украина = сколько чего конкретно?
тема ответил в Archy_k пользователя Melanxolik в Для тих, хто в пелюшках ще
Пока по тому что вы показываете затак видно в другом месте, все таки для определения действительно узкого места надо копать по глубже, гораздо глубже. Те результаты что у вас сейчас, в 8 раз отличаются от того что должно быть, соответственно подозрение что есть проблема не много в другой стороне и сперва надо все таки разобраться с ней. -
підключити сервер до двох UPS
тема ответил в olapchuk пользователя Melanxolik в Джерело безперервного живлення
Да, действительно, с просони не вник в текст. Подключайте к разным источникам, проблем нету, для этого сдвоенные БП и предназначены. Это специфика blade, в некоторых также имеются приоритеты отключения, в некоторых возможно менять приоритеты серверов для БП. Просто представьте себе, у вас в блейд каждый БП 300ват, их 5шт, суммарное потребление всеми серверами 900 ват, вот система и сохраняется, вырубая сервер с наименьшим приоритетом. -
підключити сервер до двох UPS
тема ответил в olapchuk пользователя Melanxolik в Джерело безперервного живлення
Ну можете воспользоваться гуглом) В принципе об этом много написано, в некоторых случаях что упсы должны быть разными по мощности, не соответствие в электрических характеристиках и т.д.. в общем тут ответ могут дать только электрики и apc. Но в большинстве случае умные люди правильно говорят, не занимайтесь ерундой, ибо все равно для поддержания равновесия периодами надо разряды давать, лучше раскинуть нагрузку на этих упсах так чтобы каждый держал свой независимый участок и не парился. Собственно не много тут написано о причинах почему не заводится: http://www.apcc.ru/support/forum.html?idq=1497&namet= -
підключити сервер до двох UPS
тема ответил в olapchuk пользователя Melanxolik в Джерело безперервного живлення
Обычные APC back500 не работают в такой связке. Проверяется легко, выдергиваешь шнур из первого и второй переходит на батарею. А вот здесь надо проверять, они не сгорят это точно, но вот потестить легко. -
Интернет МИКС: МИР + Украина = сколько чего конкретно?
тема ответил в Archy_k пользователя Melanxolik в Для тих, хто в пелюшках ще
напоминаю, тут совсем недавно была тема про их роутер и если вы не помните что у них в качестве бордера, то многие форумчане хорошо запомнили. -
Есть еще нюанс в топливе на дизеле, летнее и зимнее. http://www.hyperauto.ru/articles/detail.php?ID=1064
-
диаграмма направленности используемых антен, надо еще её посмотреть и может стоит в зависимости от условий скорректировать антену на аппарате и земле.
-
Интернет МИКС: МИР + Украина = сколько чего конкретно?
тема ответил в Archy_k пользователя Melanxolik в Для тих, хто в пелюшках ще
Уточните какой у вас город и все таки кто аплинк, можно в лс, тогда можно рекомендовать уже способ подхода к тестированию. -
7.46 по некоторым евпропейским направлениям в 2 раза выросли задержки.
-
Там яша днс сейчас вроде как выесжает и по пингам говорят норма, но лучше все таки локально кэшить и уже работать с кэшем.
-
Собственно проблем то нету, до какого-то момента проблем не было в обще, все работало идеально, при этом всегда использовался ближайший серве с минимальной трасой, среднее время доступа было до 3-5мс. Недавно начались веселые приключения по 30мс на доступ к ихним серверам, последняя неделя была именно такой, вчера вроде как днем начала ситуация выравниваться и какое-то время снова все было прекрасно, но потом началось снова, лихорадит хорошо. Даже банальные 30мс на ajax запросах генерируемые к поисковой системе это не сильно приятно в плане производительности, и такое поведение со стороны крупного игрока данного мира есть не совсем приятно и приемлемо. Представьте себе что внутри сети у вас несколько тысяч клиентов, большая часть из них юзает гугловые dns сервера, время доступа к этим DNS в один прекрасный момент подскочило с 2мс до 40мс, во время таких запросов требуется отрезолвить сайт. в итоге автоматом поднимается время загрузки страниц. Когда вы рекомендовали клиентам или клиенты самостоятельно устанавливали гугловые днс, как стабильные по сравнению с днс провайдера они не ожидали что в один прекрасный момент начнется такая история. Особых проблем при правильной архитектуре это не поднимает, но создает никому не нужные задержки. Опять же, тут явно лихорадит марштуры, так как видно в момент такого пика dns перестают резолвится, спасают свои кэш сервера, в итоге... Вот по этой причине и надо держать свои кэши с довольно длительным периодом хранения валидных запросов.
-
ребят, проверьте, вижу в 19.20 изменение гуглового трафика. на dns задержки упали, поисковик снова доступен на 1мс. # ping google.com PING google.com (173.194.113.201) 56(84) bytes of data. 64 bytes from 173.194.113.201: icmp_seq=1 ttl=61 time=0.796 ms 64 bytes from 173.194.113.201: icmp_seq=2 ttl=61 time=0.565 ms 64 bytes from 173.194.113.201: icmp_seq=3 ttl=61 time=0.691 ms 64 bytes from 173.194.113.201: icmp_seq=4 ttl=61 time=0.702 ms 64 bytes from 173.194.113.201: icmp_seq=5 ttl=61 time=0.580 ms ^C --- google.com ping statistics --- 5 packets transmitted, 5 received, 0% packet loss, time 4389ms rtt min/avg/max/mdev = 0.565/0.666/0.796/0.091 ms #
-
Да, ночь, видно буквы начали действительно расплываться на глаза. В общем дело ваше, можете думать как хотите и что хотите, но есть конечный результат, это работа системы 24/7 с довольно высокими нагрузками. Desktop харды дохнут примерно за 1 месяц, ваши пресловутые хитачи deskstar обрастают секторами с задержкой, мы их завозили порядка 20ти шт, в данный момент за 8 месяцев осталось всего 2а в дальнем углу, но вот те же их более серьезные Enterprise модели пока работают и проблем не показывают. От вас так и не увидел способа диагностики без первичного smart, может поделитесь? Хотя наверное ваши клиенты узнает что у него умер диск только по факту, raid вы тоже против, это ведь бессмысленная трата.
-
Вы можете считать это и сказками, но архитектура дисков Enterprise и Desktop значительно отличается, как в плане надежности, так и в плане компонентов, ну также и в определенных ситуациях и производительности. ничего не попутали? целостность данных это к FS, причем здесь smart? В случае HDD как раз smart является первичным источником для получения состояния hdd, да некоторые производители грешат тем что не все показатели записываются, не у всех алгоритмы на столько шикарные что могут отслеживать все что происходит, но как первичный источник вполне сгодится. Ну вы конечно можете считать что smart не нужен, но вот банальный пример: а как вы получите время сколько уже проработал HDD или SSD? не как и т.д. по этому и придумали smart чтобы каждый не лепил своего горбатого. Да и битая линейка памяти может повредить систему, но если посмотреть зачем ставят raid то может оказаться: 1. построение отказоустойчивых решений, где выход из строя диска и его замена не остановят систему. 2. построение производительных решений, где группы дисков обедняют в массивы (здесь есть оговорки, так как в каждом массиве может быть свое максимально комфортное количество дисков, ибо явно не стоит лупить raid 10 из 40ка дисков.) и. т.д. А вы хотите узнать о том что у вас повреждены данные или имеются проблемы исключительно от звонков пользователей и их тикетов? интересная практика. Мы с вами можем спорить и грубить друг другу на эту тему очень долго, но у каждого из нас свой опыт в построении систем, но в моем случае это не desktop и мини кластер, а вполне работающая система насчитывающая достаточное количество внутренних компонентов чтобы иметь возможность делится практически полученным опытом с другими людьми. Система должна работать, простой должен быть всегда минимальным, или сведенным на 0, а на ситуации надо реагировать оперативно. Во время сделанный backup это очень важный момент, но почему-то у нас любят их делать на тот же диск где и все данные (и не переубедишь пользователей).
-
ну зато все слушают вас) вы ж нас просвещенный. Разницу между Desktop и Enterprise знаете? подозреваю что сейчас быстро прогуглите, но собственно могу пожелать только удачи и да, hitachi enterprise серии на данный момент действительно имеют очень низкие показатели выхода из строя и возврата. ну обычно люди приводят более подробно инфу, хотя бы wd модели или их цветовую расскраску, с тошибой к счастью или к сожалению не работали, только кажется ssd приходили несколько, пока вроде работают, отказа не было. на базе чего raid? Ну тогда автору можно в обще не переживать и спать спокойно, вы ведь дали свое заключение, так что все впорядке, можно расходится.
-
тесты, сливайте данные, готовьтесь к переносу системы, винт *авно домашнее. 3.5 года отходил, надо менять.
-
http://forum.nag.ru/forum/index.php?showtopic=98864 Смотрели?