fet4
-
Всього повідомлень
539 -
Приєднався
-
Останній візит
-
Дней в лидерах
1
Тип контенту
Профили
Форум
Календарь
Все, що було написано fet4
-
Прошивка 46085 решает вопрос с загрузкой cpu, иных косяков не было замечено.
-
Ребята посоветуйте что-нибудь. 3310C. Клиенты по dhcp без relay. Не могу почти в консоли работать. Есть еще один 3310С все то же только vlan другие, так же пинги скачут. Стоит рядом же 3310B конф аналогичный все в норме цпу 20% #show cpu CPU utilization for one second: 100%; one minute: 100%; five minutes: 99% 64 bytes from 172.19.0.7: icmp_seq=392 ttl=255 time=3319 ms 64 bytes from 172.19.0.7: icmp_seq=393 ttl=255 time=2322 ms 64 bytes from 172.19.0.7: icmp_seq=394 ttl=255 time=1314 ms 64 bytes from 172.19.0.7: icmp_seq=395 ttl=255 time=307 ms 64 bytes from 172.19.0.7: icmp_seq=396 ttl=255 time=2029 ms 64 bytes from 172.19.0.7: icmp_seq=397 ttl=255 time=1536 ms 64 bytes from 172.19.0.7: icmp_seq=398 ttl=255 time=530 ms 64 bytes from 172.19.0.7: icmp_seq=399 ttl=255 time=51.2 ms 64 bytes from 172.19.0.7: icmp_seq=400 ttl=255 time=601 ms 64 bytes from 172.19.0.7: icmp_seq=401 ttl=255 time=2202 ms 64 bytes from 172.19.0.7: icmp_seq=402 ttl=255 time=1194 ms 64 bytes from 172.19.0.7: icmp_seq=403 ttl=255 time=187 ms 64 bytes from 172.19.0.7: icmp_seq=404 ttl=255 time=1752 ms 64 bytes from 172.19.0.7: icmp_seq=405 ttl=255 time=758 ms 64 bytes from 172.19.0.7: icmp_seq=406 ttl=255 time=282 ms 64 bytes from 172.19.0.7: icmp_seq=407 ttl=255 time=335 ms 64 bytes from 172.19.0.7: icmp_seq=408 ttl=255 time=370 ms !version 10.1.0D build 33463 service timestamps log date service timestamps debug date logging 172.19.0.1 no logging console no logging monitor logging trap debugging ! hostname OLT3 port-protected 1 ! ! ! ! ip default-gateway 172.19.0.1 ! ! no spanning-tree ! ! epon dba hardware dynamic-cycletime discovery-frequence 60 discovery-length 1024 ! aaa authentication login default local aaa authentication enable default none aaa authorization exec default local ! username maxi password 0 xxxxxxx ! ! epon oam-version 1 0x21 epon oam-version 2 0x20 ! epon onu-config-template epon1 cmd-sequence 1 epon onu all-port ctc vlan mode tag 129 cmd-sequence 2 epon sla downstream pir 1000000 cir 10000 cmd-sequence 3 epon sla upstream pir 1000000 cir 10000 cmd-sequence 4 epon onu all-port storm-control mode 4 threshold 256 cmd-sequence 5 epon onu all-port ctc loopback detect cmd-sequence 6 switchport port-security mode dynamic cmd-sequence 7 switchport port-security dynamic maximum 10 ! epon onu-config-template epon2 cmd-sequence 1 epon onu all-port ctc vlan mode tag 130 cmd-sequence 2 epon sla downstream pir 1000000 cir 10000 cmd-sequence 3 epon sla upstream pir 1000000 cir 10000 cmd-sequence 4 epon onu all-port storm-control mode 4 threshold 256 cmd-sequence 5 epon onu all-port ctc loopback detect cmd-sequence 6 switchport port-security mode dynamic cmd-sequence 7 switchport port-security dynamic maximum 10 ! epon onu-config-template epon3 cmd-sequence 1 epon onu all-port ctc vlan mode tag 131 cmd-sequence 2 epon sla downstream pir 1000000 cir 10000 cmd-sequence 3 epon sla upstream pir 1000000 cir 10000 cmd-sequence 4 epon onu all-port storm-control mode 4 threshold 256 cmd-sequence 5 epon onu all-port ctc loopback detect cmd-sequence 6 switchport port-security mode dynamic cmd-sequence 7 switchport port-security dynamic maximum 10 ! epon onu-config-template epon4 cmd-sequence 1 epon onu all-port ctc vlan mode tag 132 cmd-sequence 2 epon sla downstream pir 1000000 cir 10000 cmd-sequence 3 epon sla upstream pir 1000000 cir 10000 cmd-sequence 4 epon onu all-port storm-control mode 4 threshold 256 cmd-sequence 5 epon onu all-port ctc loopback detect cmd-sequence 6 switchport port-security mode dynamic cmd-sequence 7 switchport port-security dynamic maximum 2 ! ! !!slot 0 89 interface GigaEthernet0/1 description UPLINK switchport trunk vlan-allowed 10,129-132 switchport trunk vlan-untagged none switchport mode trunk dhcp snooping trust arp inspection trust ip-source trust ! interface GigaEthernet0/2 shutdown ! interface GigaEthernet0/3 shutdown ! interface GigaEthernet0/4 shutdown ! interface GigaEthernet0/5 shutdown ! interface GigaEthernet0/6 shutdown ! interface EPON0/1 epon pre-config-template epon1 binded-onu-llid 1-64 epon bind-onu mac e067.b317.ab9a 1 epon bind-onu mac 00d0.d049.1f4f 2 epon bind-onu mac e067.b317.ab9e 3 epon bind-onu mac e067.b317.ab92 4 epon bind-onu mac e067.b317.a466 5 epon bind-onu mac fcfa.f72b.7fa4 6 epon bind-onu mac fcfa.f716.011f 7 epon bind-onu mac 8014.a81f.1678 8 epon bind-onu mac fcfa.f7c5.b488 9 epon bind-onu mac fcfa.f72b.8048 10 epon bind-onu mac e067.b317.a9e2 11 epon bind-onu mac fcfa.f72b.8164 12 epon bind-onu mac e067.b317.a3ba 13 epon bind-onu mac 1c87.7912.646c 14 epon bind-onu mac fcfa.f796.29cd 15 epon bind-onu mac e067.b317.a388 16 epon bind-onu mac e067.b317.a60c 17 epon bind-onu mac 8014.a81f.3a40 18 epon bind-onu mac e067.b317.a38a 19 epon bind-onu mac fcfa.f7c5.f7fa 20 epon bind-onu mac fcfa.f7c5.cfe6 21 epon bind-onu mac fcfa.f7c5.cf7d 22 epon bind-onu mac fcfa.f72b.7e16 23 epon bind-onu mac fcfa.f7c5.cdd5 24 epon bind-onu mac fcfa.f72b.8606 25 epon bind-onu mac 8014.a81f.3a48 26 epon bind-onu mac e067.b315.342a 27 epon bind-onu mac 8014.a81e.d610 28 epon bind-onu mac e067.b312.db8f 29 epon bind-onu mac fcfa.f7c6.05c9 30 epon bind-onu mac fcfa.f796.29ab 31 epon bind-onu mac e067.b315.2ce4 32 epon bind-onu mac fcfa.f7c5.cdc2 33 epon bind-onu mac fcfa.f716.4b07 34 epon bind-onu mac fcfa.f716.00d2 35 epon bind-onu mac fcfa.f7c5.cf90 36 epon bind-onu mac fcfa.f7c6.019a 37 epon bind-onu mac fcfa.f72b.7d1e 38 epon bind-onu mac fcfa.f7c5.ce98 39 epon bind-onu mac fcfa.f716.33e3 40 epon bind-onu mac fcfa.f72b.830a 41 epon bind-onu mac fcfa.f716.1e4a 42 epon bind-onu mac e067.b312.d9a5 43 epon bind-onu mac fcfa.f7c5.f8d1 44 epon bind-onu mac e067.b317.aba4 45 epon bind-onu mac e067.b317.a27e 46 epon bind-onu mac e067.b317.a244 47 switchport trunk vlan-allowed 129 switchport mode trunk switchport protected 1 ! interface EPON0/2 epon pre-config-template epon2 binded-onu-llid 1-64 epon bind-onu mac fcfa.f716.0162 1 epon bind-onu mac e067.b317.441d 2 epon bind-onu mac e067.b314.d8d8 3 epon bind-onu mac fcfa.f716.3366 4 epon bind-onu mac fcfa.f796.2afb 5 epon bind-onu mac fcfa.f7c5.cb46 6 epon bind-onu mac fcfa.f72b.85a7 7 epon bind-onu mac fcfa.f716.0056 8 epon bind-onu mac fcfa.f7c6.02a4 9 epon bind-onu mac fcfa.f72b.85e8 10 epon bind-onu mac fcfa.f7c5.b483 11 epon bind-onu mac fcfa.f7c5.b3d6 12 epon bind-onu mac fcfa.f7c5.f878 13 epon bind-onu mac fcfa.f716.4c36 14 epon bind-onu mac fcfa.f7c6.05c7 15 epon bind-onu mac fcfa.f72b.88b1 16 epon bind-onu mac fcfa.f7c5.cf23 17 epon bind-onu mac fcfa.f7c5.f271 18 epon bind-onu mac 1c87.7912.645e 19 epon bind-onu mac 8014.a81e.d618 20 epon bind-onu mac fcfa.f7c5.b3df 21 epon bind-onu mac e067.b317.aba0 22 epon bind-onu mac e067.b317.a274 23 epon bind-onu mac e067.b317.a23a 24 epon bind-onu mac e067.b317.ada8 25 epon bind-onu mac c83a.35b4.52c9 26 epon bind-onu mac fcfa.f796.29c0 27 epon bind-onu mac e067.b315.33b2 28 epon bind-onu mac e067.b315.33b8 29 epon bind-onu mac e067.b315.33ac 30 epon bind-onu mac e067.b315.3430 31 epon bind-onu mac e067.b315.33a8 32 epon bind-onu mac e067.b315.3304 33 epon bind-onu mac e067.b315.3754 34 epon bind-onu mac e067.b315.3426 35 epon bind-onu mac e067.b315.3428 36 epon bind-onu mac e067.b315.3424 37 epon bind-onu mac e067.b315.342e 38 epon bind-onu mac e067.b315.33ae 39 epon bind-onu mac e067.b315.376c 40 epon bind-onu mac e067.b315.376a 41 epon bind-onu mac e067.b315.377a 42 epon bind-onu mac e067.b315.3788 43 epon bind-onu mac e067.b31b.4329 44 epon bind-onu mac e067.b31b.4323 45 epon bind-onu mac e067.b31b.4317 46 epon bind-onu mac e067.b31b.4347 47 epon bind-onu mac e067.b31b.4341 48 epon bind-onu mac e067.b31b.4335 49 epon bind-onu mac e067.b31b.433e 50 epon bind-onu mac e067.b31b.42f3 51 epon bind-onu mac e067.b31b.4320 52 epon bind-onu mac e067.b31b.4344 53 epon bind-onu mac e067.b31b.4314 54 epon bind-onu mac e067.b31b.4305 55 epon bind-onu mac e067.b31b.4308 56 epon bind-onu mac e067.b31b.431a 57 epon bind-onu mac e067.b31b.431d 58 epon bind-onu mac e067.b318.271a 59 epon bind-onu mac e067.b318.2704 60 epon bind-onu mac e067.b318.2722 61 epon bind-onu mac e067.b318.2710 62 epon bind-onu mac e067.b318.270a 63 switchport trunk vlan-allowed 130 switchport mode trunk switchport protected 1 ! interface EPON0/3 epon pre-config-template epon3 binded-onu-llid 1-64 epon bind-onu mac e067.b317.a8f2 1 epon bind-onu mac e067.b317.a8f8 2 epon bind-onu mac e067.b317.a380 3 epon bind-onu mac fcfa.f796.8241 4 switchport trunk vlan-allowed 131 switchport mode trunk switchport protected 1 interface EPON0/4 epon pre-config-template epon4 binded-onu-llid 1-64 switchport trunk vlan-allowed 132 switchport mode trunk switchport protected 1 ! !!slot end ! interface VLAN10 ip address 172.19.0.7 255.255.255.0 ! ! ! vlan 10 name managment ! vlan 129 name Internet_epon1 ! vlan 130 name Internet_epon2 ! vlan 1,10,129-132 ! ! ! ! ip dhcp-relay snooping ip dhcp-relay snooping vlan 129-132 ip arp inspection vlan 129-132 ip verify source vlan 129-132 ip dhcp-relay snooping information option format hn-type host ip dhcp-relay snooping log ! ! ! ! ! snmp-server community 0 public RO snmp-server contact snmp-server location per_Prostornij_8 ! line vty 0 exec-timeout 0 ! line vty 1 exec-timeout 0 ! line vty 2 exec-timeout 0 ! line vty 3 exec-timeout 0 ! line vty 4 exec-timeout 0 ! line vty 5 exec-timeout 0 ! line vty 6 exec-timeout 0 ! line vty 7 exec-timeout 0 ! line vty 8 exec-timeout 0 ! line vty 9 exec-timeout 0 ! line vty 10 exec-timeout 0 ! line vty 11 exec-timeout 0 ! line vty 12 exec-timeout 0 ! line vty 13 exec-timeout 0 ! line vty 14 exec-timeout 0 ! line vty 15 exec-timeout 0 ! line vty 16 exec-timeout 0 ! line vty 17 exec-timeout 0 ! line vty 18 exec-timeout 0 ! line vty 19 exec-timeout 0 ! line vty 20 exec-timeout 0 ! line vty 21 exec-timeout 0 ! line vty 22 exec-timeout 0 ! line vty 23 exec-timeout 0 ! line vty 24 exec-timeout 0 ! line vty 25 exec-timeout 0 ! line vty 26 exec-timeout 0 ! line vty 27 exec-timeout 0 ! line vty 28 exec-timeout 0 ! line vty 29 exec-timeout 0 ! line vty 30 exec-timeout 0 ! line vty 31 exec-timeout 0 ! ! ! ip sshd silence-period 3600 ip sshd timeout 60 ip sshd enable ! time-zone Kyiv 2 0 ntp server 172.19.0.1 ! !Pending configurations for absent linecards: ! !No configurations pending global
-
А зачем вы 125 влан транком и антагом отдаете?
-
Все оказалось гораздо проще. Сравнив показания conntrack -C на бордере и брасе, разница была огромна примерно 300 000/30 000 соответственно в тот момент, я понял что нужно искать проблему где-то в транзите. Т.к. фаервол был не дописан, ограничив на бордере FORWARD исключительно клиентам, сразу же количество conntrack -C выровнялось. Вот уже 3-ий день все тихо. :FORWARD DROP [24852758:1686709141] :forward_new - [0:0] -A FORWARD -m conntrack --ctstate INVALID -j DROP -A FORWARD -p tcp -m set --match-set blacklist dst -j REJECT --reject-with tcp-reset -A FORWARD -m set --match-set blacklist dst -j REJECT --reject-with icmp-port-unreachable -A FORWARD -m conntrack --ctstate RELATED,ESTABLISHED -j ACCEPT -A FORWARD -m conntrack --ctstate NEW -j forward_new -A forward_new -i vlan10 -m set --match-set ip_pools src -j ACCEPT -A forward_new -o vlan10 -m set --match-set ip_pools dst -j ACCEPT
-
Чего боялся то и произошло. nf_conntrack_tuple_taken снова вылез в 100% загрузки нового проца. На брасе все окей никаких аномалий не видно. Даже не знаю уже что и думать. Может ядро обновить/откатить?

-
Вовсе не обязательно.Весь блок IP уже смаршрутизирован на ваш бордер аплинкером, а может сервер работать без прописанных адресов или нет - сугубо ограничение софта и вашей конфигурации. Допустим аплинкер смаршрутизировал блок 192.168.1.0/24 на 192.168.0.1, на 192.168.0.1 натится этот блок. -A POSTROUTING -o vlan2000 -j SNAT --to-source 192.168.1.1-192.168.1.254 --persistent Как аплинкер понимает что сначеный блок прилетает именно от 192.168.0.1 если весь трафик с интерфейса натится в блок ? Или где-то в пакете есть адрес маршрутизатора ?
-
Вчера купил новый проц из того что было по месту и поставил. Надеюсь это решит проблему. Architecture: x86_64 CPU op-mode(s): 32-bit, 64-bit Byte Order: Little Endian CPU(s): 4 On-line CPU(s) list: 0-3 Thread(s) per core: 1 Core(s) per socket: 4 Socket(s): 1 NUMA node(s): 1 Vendor ID: GenuineIntel CPU family: 6 Model: 158 Model name: Intel(R) Core(TM) i7-7700 CPU @ 3.60GHz Stepping: 9 CPU MHz: 4000.122 CPU max MHz: 4200,0000 CPU min MHz: 800,0000 BogoMIPS: 7200.00 Virtualization: VT-x L1d cache: 32K L1i cache: 32K L2 cache: 256K L3 cache: 8192K NUMA node0 CPU(s): 0-3 Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc aperfmperf eagerfpu pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch intel_pt tpr_shadow vnmi flexpriority ept vpid fsgsbase tsc_adjust bmi1 hle avx2 smep bmi2 erms invpcid rtm mpx rdseed adx smap clflushopt xsaveopt xsavec xgetbv1 xsaves dtherm ida arat pln pts hwp hwp_notify hwp_act_window hwp_epp Так же при возможности сделал lacp из двух интерфейсов. Но нормального баланса между сетевыми не увидел видимо потому что там уже L3 трафик. Можно ли это как-то улучшить? Или как правильно с аггрегировать два интерфейса в данном случае? На стороне сервера ip link add name bond0 type bond ip link set dev bond0 type bond mode 802.3ad ip link set dev enp1s0f0 master bond0 ip link set dev enp1s0f1 master bond0 ip link set dev bond0 up На свитче просто lacp на интерфейсах. port-channel появился. Так же при загрузке система конфигурируется командами. Подскажите все ли они нужны и правильные значения. ethtool -K enp1s0f0/enp1s0f1 rx off ethtool -K enp1s0f0/enp1s0f1 tx off ethtool -K enp1s0f0/enp1s0f1 tso off ethtool -K enp1s0f0/enp1s0f1 ufo off ethtool -K enp1s0f0/enp1s0f1 gso off ethtool -K enp1s0f0/enp1s0f1 gro off ethtool -K enp1s0f0/enp1s0f1 lro off ethtool -K enp1s0f0/enp1s0f1 rxvlan off ethtool -K enp1s0f0/enp1s0f1 txvlan off ethtool -K enp1s0f0/enp1s0f1 rxhash off ethtool -G enp1s0f0/enp1s0f1 rx 2048 tx 2048 ethtool -C enp1s0f0/enp1s0f1 adaptive-rx off adaptive-tx off rx-usecs 0 tx-usecs 0 ethtool -A enp1s0f0/enp1s0f1 autoneg off rx off tx off echo 409600 > /proc/sys/net/netfilter/nf_conntrack_buckets echo 1638400 > /proc/sys/net/netfilter/nf_conntrack_max echo 1638400 > /proc/sys/net/nf_conntrack_max echo 600 > /proc/sys/net/netfilter/nf_conntrack_tcp_timeout_established for x in 0 1 2 3; do echo performance > /sys/devices/system/cpu/cpu${x}/cpufreq/scaling_governor; done echo 250000 > /proc/sys/net/core/netdev_max_backlog echo 4194304 > /proc/sys/net/core/rmem_max echo 4194304 > /proc/sys/net/core/wmem_max echo 4194304 > /proc/sys/net/core/rmem_default echo 4194304 > /proc/sys/net/core/wmem_default echo 4194304 > /proc/sys/net/core/optmem_max echo 0 > /proc/sys/net/ipv4/tcp_timestamps echo 1 > /proc/sys/net/ipv4/tcp_sack echo "4096 87380 4194304" > /proc/sys/net/ipv4/tcp_rmem echo "4096 65536 4194304" > /proc/sys/net/ipv4/tcp_wmem echo 1 > /proc/sys/net/ipv4/tcp_low_latency echo 1 > /proc/sys/net/ipv4/tcp_adv_win_scale echo 0 > /sys/block/sda/queue/add_random echo 2 > /sys/block/sda/queue/nomerges echo 1 > /proc/sys/net/ipv6/conf/all/disable_ipv6 echo 1 > /proc/sys/net/ipv6/conf/default/disable_ipv6 echo 1 > /proc/sys/net/ipv4/ip_forward Прерывания раскинуты так. По ядрам загрузка одинаковая. # cat /proc/interrupts CPU0 CPU1 CPU2 CPU3 25: 1 0 0 0 PCI-MSI 524288-edge enp1s0f0 26: 2 0 311210732 0 PCI-MSI 524289-edge enp1s0f0-rx-0 27: 2 401254667 0 0 PCI-MSI 524290-edge enp1s0f0-rx-1 28: 357244949 0 0 0 PCI-MSI 524291-edge enp1s0f0-rx-2 29: 2 0 0 332343761 PCI-MSI 524292-edge enp1s0f0-rx-3 30: 2 0 503810318 0 PCI-MSI 524293-edge enp1s0f0-tx-0 31: 2 632697195 0 0 PCI-MSI 524294-edge enp1s0f0-tx-1 32: 568941065 0 0 0 PCI-MSI 524295-edge enp1s0f0-tx-2 33: 2 0 0 610190740 PCI-MSI 524296-edge enp1s0f0-tx-3 34: 0 0 0 0 PCI-MSI 327680-edge xhci_hcd 35: 30998 0 0 0 PCI-MSI 376832-edge ahci[0000:00:17.0] 36: 1 0 0 0 PCI-MSI 526336-edge enp1s0f1 37: 2 91729771 0 0 PCI-MSI 526337-edge enp1s0f1-rx-0 38: 85566388 0 0 0 PCI-MSI 526338-edge enp1s0f1-rx-1 39: 2 0 0 81042615 PCI-MSI 526339-edge enp1s0f1-rx-2 40: 2 0 93399072 0 PCI-MSI 526340-edge enp1s0f1-rx-3 41: 2 51965963 0 0 PCI-MSI 526341-edge enp1s0f1-tx-0 42: 51814256 0 0 0 PCI-MSI 526342-edge enp1s0f1-tx-1 43: 2 0 0 58165807 PCI-MSI 526343-edge enp1s0f1-tx-2 44: 2 0 55823007 0 PCI-MSI 526344-edge enp1s0f1-tx-3 Oct 24 21:11:05 kernel: [ 0.720422] igb: Intel(R) Gigabit Ethernet Network Driver - version 5.4.0-k Oct 24 21:11:05 kernel: [ 0.720586] igb: Copyright (c) 2007-2014 Intel Corporation. Oct 24 21:11:05 kernel: [ 0.765113] igb 0000:01:00.0: added PHC on eth0 Oct 24 21:11:05 kernel: [ 0.765248] igb 0000:01:00.0: Intel(R) Gigabit Ethernet Network Connection Oct 24 21:11:05 kernel: [ 0.765391] igb 0000:01:00.0: eth0: (PCIe:5.0Gb/s:Width x4) f4:ce:46:a6:57:38 Oct 24 21:11:05 kernel: [ 0.765530] igb 0000:01:00.0: eth0: PBA No: Unknown Oct 24 21:11:05 kernel: [ 0.765671] igb 0000:01:00.0: Using MSI-X interrupts. 4 rx queue(s), 4 tx queue(s) Oct 24 21:11:05 kernel: [ 0.809537] igb 0000:01:00.1: added PHC on eth1 Oct 24 21:11:05 kernel: [ 0.809759] igb 0000:01:00.1: Intel(R) Gigabit Ethernet Network Connection Oct 24 21:11:05 kernel: [ 0.810002] igb 0000:01:00.1: eth1: (PCIe:5.0Gb/s:Width x4) f4:ce:46:a6:57:39 Oct 24 21:11:05 kernel: [ 0.810241] igb 0000:01:00.1: eth1: PBA No: Unknown Oct 24 21:11:05 kernel: [ 0.810415] igb 0000:01:00.1: Using MSI-X interrupts. 4 rx queue(s), 4 tx queue(s) Oct 24 21:11:05 kernel: [ 0.853916] igb 0000:01:00.2: added PHC on eth2 Oct 24 21:11:05 kernel: [ 0.854120] igb 0000:01:00.2: Intel(R) Gigabit Ethernet Network Connection Oct 24 21:11:05 kernel: [ 0.854319] igb 0000:01:00.2: eth2: (PCIe:5.0Gb/s:Width x4) f4:ce:46:a6:57:3a Oct 24 21:11:05 kernel: [ 0.854534] igb 0000:01:00.2: eth2: PBA No: Unknown Oct 24 21:11:05 kernel: [ 0.854732] igb 0000:01:00.2: Using MSI-X interrupts. 4 rx queue(s), 4 tx queue(s) Oct 24 21:11:05 kernel: [ 0.898870] igb 0000:01:00.3: added PHC on eth3 Oct 24 21:11:05 kernel: [ 0.899047] igb 0000:01:00.3: Intel(R) Gigabit Ethernet Network Connection Oct 24 21:11:05 kernel: [ 0.899262] igb 0000:01:00.3: eth3: (PCIe:5.0Gb/s:Width x4) f4:ce:46:a6:57:3b Oct 24 21:11:05 kernel: [ 0.899458] igb 0000:01:00.3: eth3: PBA No: Unknown Oct 24 21:11:05 kernel: [ 0.899652] igb 0000:01:00.3: Using MSI-X interrupts. 4 rx queue(s), 4 tx queue(s) Oct 24 21:11:05 kernel: [ 0.901747] igb 0000:01:00.2 enp1s0f2: renamed from eth2 Oct 24 21:11:05 kernel: [ 0.939336] igb 0000:01:00.1 enp1s0f1: renamed from eth1 Oct 24 21:11:05 kernel: [ 0.963379] igb 0000:01:00.3 enp1s0f3: renamed from eth3 Oct 24 21:11:05 kernel: [ 1.023273] igb 0000:01:00.0 enp1s0f0: renamed from eth0 Oct 24 21:11:09 kernel: [ 5.247550] igb 0000:01:00.0 enp1s0f0: igb: enp1s0f0 NIC Link is Up 1000 Mbps Full Duplex, Flow Control: None Oct 24 21:11:09 kernel: [ 5.315550] igb 0000:01:00.1 enp1s0f1: igb: enp1s0f1 NIC Link is Up 1000 Mbps Full Duplex, Flow Control: None В сети читал что если NAT происходит на пул адресов, то нужно все эти ip вешать алиасами куда-то для меньшей нагрузки на проц. Так ли это? Сейчас и без это работает.
-
Завтра буду проц ехать брать, ничего не поменялось. Стоит ли за i7 переплачивать? ноудени+ , dhcp + pppoe, от pppoe потихоньку избавляюсь. Нынешняя балансировка по src работает адекватно, разнится в загрузке каналов примерно 50-100Мбит что для меня в принципе подходит.
-
Установил я в груб. processor.max_cstate=1 intel_idle.max_cstate=0 Перезагрузился и в биосе отключил c-state_ы, установил max-perfomance на память. Потом увеличил в 25-раз conntrack относительно default. Получилось. net.netfilter.nf_conntrack_buckets = 409600 net.netfilter.nf_conntrack_count = 765844 net.netfilter.nf_conntrack_max = 1638400 net.nf_conntrack_max = 1638400 Моментально вылез в топы cpu nf_conntrack_tuple_taken но быстро в теч 5 мин. попустило сервак. Видимо из-за уменьшенной таблицы conntrack. Наблюдаю и параллельно думаю о новом проце. Что посоветуете на LGA1151 в моем случае? Есть рядом аналогичный тазик по характеристикам может лучше балансировать трафик между ними двумя, один аплинк в один, другой во второй? Заранее спасибо за советы.
-
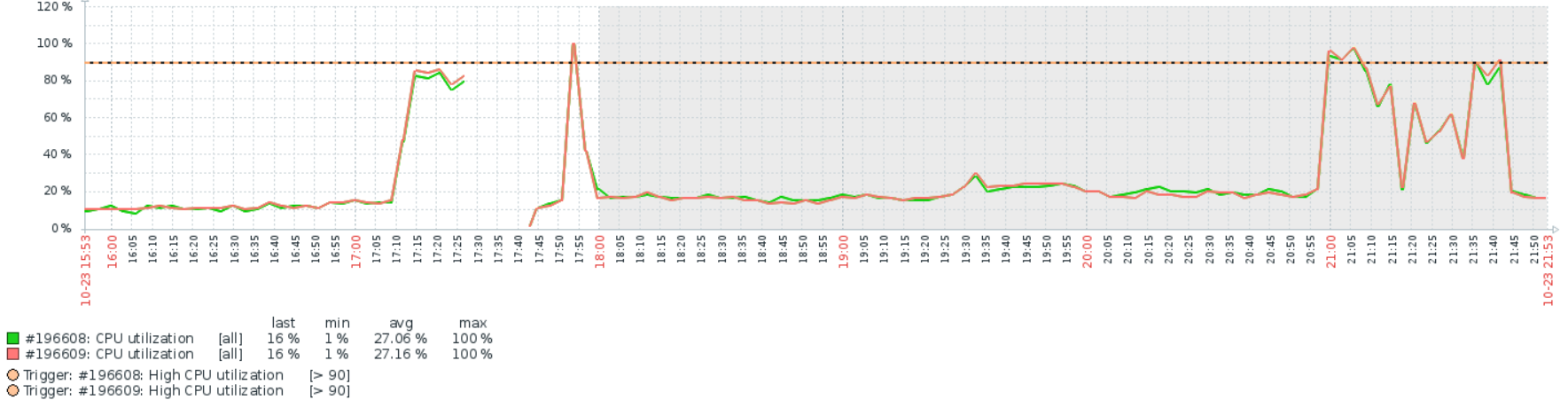
вывод top но уже когда глюк прошел. надо будет посмотреть память в момент глюка. top - 20:29:05 up 10 days, 1:32, 2 users, load average: 0,00, 0,00, 0,00 Tasks: 104 total, 1 running, 103 sleeping, 0 stopped, 0 zombie %Cpu(s): 0,0 us, 0,0 sy, 0,0 ni, 90,1 id, 0,0 wa, 0,0 hi, 9,9 si, 0,0 st KiB Mem : 3935492 total, 2734828 free, 789892 used, 410772 buff/cache KiB Swap: 1951740 total, 1951740 free, 0 used. 2870248 avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 28560 root 20 0 300236 130960 7960 S 0,3 3,3 0:08.86 perf_4.9 29403 root 20 0 33304 17476 3612 S 0,0 0,4 0:01.42 bash 542 Debian-+ 20 0 58620 11516 6404 S 0,0 0,3 11:47.99 snmpd 205 root 20 0 64136 8260 7724 S 0,0 0,2 1:59.97 systemd-journal 1 root 20 0 57248 7088 5344 S 0,0 0,2 0:06.66 systemd 29137 root 20 0 95168 6896 5928 S 0,0 0,2 0:00.00 sshd 27235 root 20 0 95168 6744 5776 S 0,0 0,2 0:00.04 sshd 523 root 20 0 69944 6212 5440 S 0,0 0,2 0:00.03 sshd 27237 maxi 20 0 64876 6060 5216 S 0,0 0,2 0:00.00 systemd 27278 root 20 0 21344 5340 3436 S 0,0 0,1 0:01.50 bash 27245 maxi 20 0 21004 4856 3372 S 0,0 0,1 0:00.04 bash 29143 maxi 20 0 95300 4792 3704 S 0,0 0,1 0:00.22 sshd 29144 maxi 20 0 21004 4684 3196 S 0,0 0,1 0:00.07 bash 341 root 20 0 46504 4680 4112 S 0,0 0,1 0:01.17 systemd-logind 27244 maxi 20 0 95168 4284 3276 S 0,0 0,1 0:00.63 sshd 276 systemd+ 20 0 127284 4180 3684 S 0,0 0,1 0:01.06 systemd-timesyn 29382 root 20 0 49540 3988 3420 S 0,0 0,1 0:00.00 sudo 14397 root 20 0 44916 3880 3244 R 0,3 0,1 0:00.02 top 342 root 20 0 250116 3824 2476 S 0,0 0,1 0:21.50 rsyslogd 27277 root 20 0 49540 3824 3252 S 0,0 0,1 0:00.05 sudo 343 message+ 20 0 45116 3760 3320 S 0,0 0,1 0:00.69 dbus-daemon 222 root 20 0 45480 3644 2908 S 0,0 0,1 0:00.77 systemd-udevd 14405 root 20 0 11176 3024 2800 S 0,0 0,1 0:00.00 uplink-check 14406 root 20 0 11176 3024 2800 S 0,0 0,1 0:00.00 uplink-check 544 root 20 0 28424 2944 2536 S 0,0 0,1 0:00.07 vsftpd 561 quagga 20 0 24872 2832 1828 S 0,0 0,1 0:00.04 zebra 340 root 20 0 29636 2812 2560 S 0,0 0,1 0:15.75 cron 14399 root 20 0 48824 2696 2308 S 0,0 0,1 0:00.00 cron 14398 root 20 0 48824 2692 2304 S 0,0 0,1 0:00.00 cron 574 quagga 20 0 30252 2556 1668 S 0,0 0,1 1:24.30 ospfd 9413 root 20 0 14536 1868 1732 S 0,0 0,0 0:00.00 agetty 9420 root 20 0 14536 1868 1732 S 0,0 0,0 0:00.00 agetty 27238 maxi 20 0 82572 1672 4 S 0,0 0,0 0:00.00 (sd-pam) 14414 root 20 0 17840 1260 1132 S 0,0 0,0 0:00.00 ping 14413 root 20 0 17840 1244 1120 S 0,0 0,0 0:00.00 ping 14403 root 20 0 4288 804 724 S 0,0 0,0 0:00.00 sh 14402 root 20 0 4288 720 644 S 0,0 0,0 0:00.00 sh
-
to Kayot Если не может тогда поменяю. Просто смотрю загрузка не большая проца, а как еще понять что он уже на подходе хз. intel_idle.max_cstate=0 processor.max_cstate=1 уже добавил сейчас перегружусь посмотрим. Какой запас контрак таблицы и таблицы хешей 2-х кратный сделать? И контрак таблица=таблица хешей или контрак таблица в 4 раза больше хешей?
-
Найдем если проблема в нем будет. А чего ждать от бюджетного оборудования для десктопов? Я бы взял что то из "серверного". Вы думаете процесс nf_conntrack_tuple_taken, на другом проце не будет его так съедать? Как по мне это программный бок.
-
Найдем если проблема в нем будет.
-
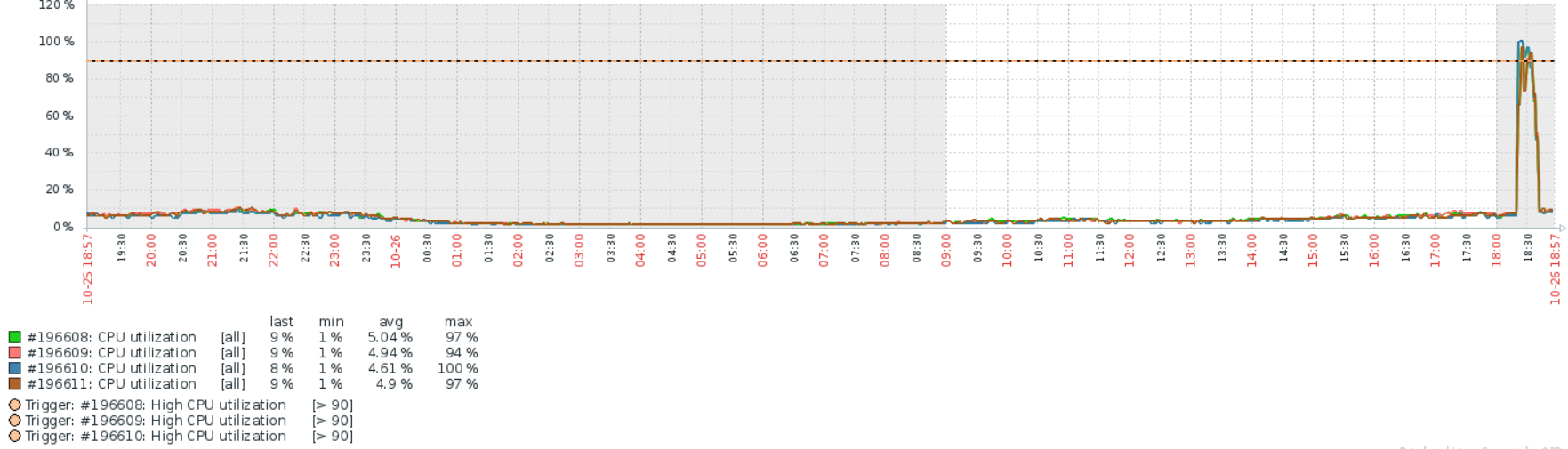
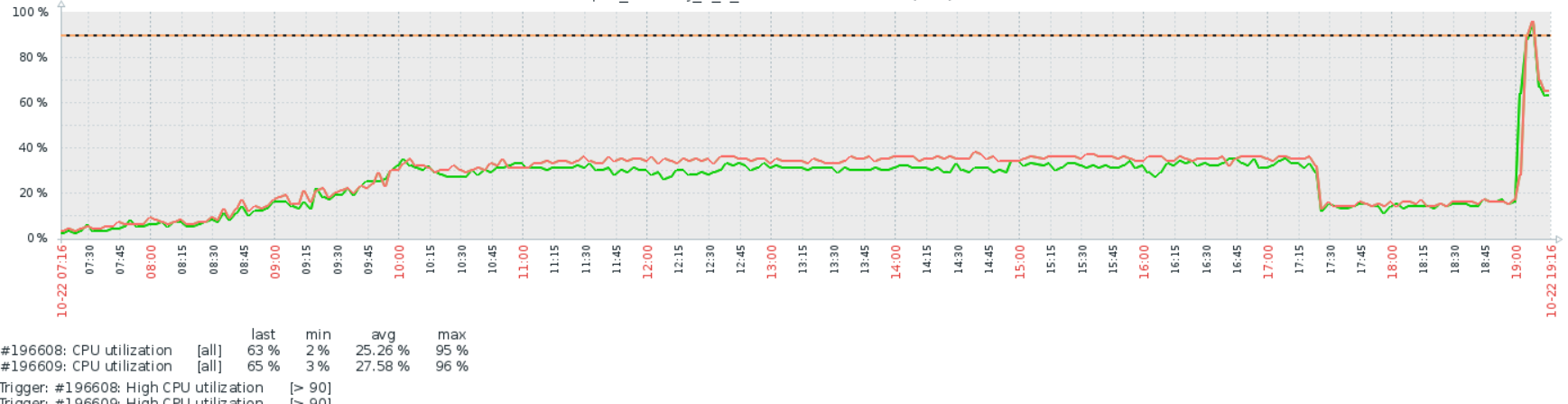
Спасибо всем за подсказки, как говорится век живи век учись! Сделал echo performance > /sys/devices/system/cpu/cpu0/cpufreq/scaling_governor echo performance > /sys/devices/system/cpu/cpu1/cpufreq/scaling_governor Нагрузка упала на 20%. Стоял режим powersaving. Сделал еще некоторые рекомендации с мануала на первой странице. Потом вылез баг о котором я говорил, но теперь машинка доступна, лагает но доступна. perf-top показывает 81,93% [kernel] [k] nf_conntrack_tuple_taken 3,80% [kernel] [k] hash_conntrack_raw 1,50% [kernel] [k] nf_nat_cleanup_conntrack 1,20% [kernel] [k] fib_table_lookup 1,12% [kernel] [k] nf_nat_used_tuple 1,10% [kernel] [k] ip_finish_output 1,10% [kernel] [k] __local_bh_enable_ip 0,84% [kernel] [k] _cond_resched 0,65% [kernel] [k] hash_net4_test 0,65% [kernel] [k] native_irq_return_iret 0,57% [kernel] [k] do_csum 0,51% [kernel] [k] nf_ct_invert_tuple 0,49% [kernel] [k] ip_rcv 0,49% [kernel] [k] set_match_v4 0,38% [kernel] [k] ipv4_invert_tuple 0,38% [kernel] [k] __skb_flow_dissect # uname -a Linux fibernet-router 4.9.0-3-amd64 #1 SMP Debian 4.9.30-2+deb9u3 (2017-08-06) x86_64 GNU/Linux Что это такой за зверь nf_conntrack_tuple_taken ? # sysctl -a | grep conntrack net.netfilter.nf_conntrack_acct = 0 net.netfilter.nf_conntrack_buckets = 2621440 net.netfilter.nf_conntrack_checksum = 1 net.netfilter.nf_conntrack_count = 873819 net.netfilter.nf_conntrack_events = 1 net.netfilter.nf_conntrack_expect_max = 256 net.netfilter.nf_conntrack_generic_timeout = 600 net.netfilter.nf_conntrack_helper = 0 net.netfilter.nf_conntrack_icmp_timeout = 30 net.netfilter.nf_conntrack_log_invalid = 0 net.netfilter.nf_conntrack_max = 104857600 net.netfilter.nf_conntrack_tcp_be_liberal = 0 net.netfilter.nf_conntrack_tcp_loose = 1 net.netfilter.nf_conntrack_tcp_max_retrans = 3 net.netfilter.nf_conntrack_tcp_timeout_close = 10 net.netfilter.nf_conntrack_tcp_timeout_close_wait = 60 net.netfilter.nf_conntrack_tcp_timeout_established = 600 net.netfilter.nf_conntrack_tcp_timeout_fin_wait = 120 net.netfilter.nf_conntrack_tcp_timeout_last_ack = 30 net.netfilter.nf_conntrack_tcp_timeout_max_retrans = 300 net.netfilter.nf_conntrack_tcp_timeout_syn_recv = 60 net.netfilter.nf_conntrack_tcp_timeout_syn_sent = 120 net.netfilter.nf_conntrack_tcp_timeout_time_wait = 120 net.netfilter.nf_conntrack_tcp_timeout_unacknowledged = 300 net.netfilter.nf_conntrack_timestamp = 0 net.netfilter.nf_conntrack_udp_timeout = 30 net.netfilter.nf_conntrack_udp_timeout_stream = 180 net.nf_conntrack_max = 104857600 :~# iptables-save # Generated by iptables-save v1.6.0 on Sun Oct 22 19:26:25 2017 *nat :PREROUTING ACCEPT [409638580:29898948645] :INPUT ACCEPT [10046:1242872] :OUTPUT ACCEPT [64093:3401668] :POSTROUTING ACCEPT [2506521:101946456] :dnat_post - [0:0] :dnat_pre - [0:0] -A PREROUTING -d x.x.x.x -m set --match-set dnat_ports dst -j dnat_pre -A OUTPUT -d x.x.x.x -m set --match-set dnat_ports dst -j dnat_pre -A POSTROUTING -m set --match-set ip_pools src -m set --match-set dnat_ports dst -j dnat_post -A POSTROUTING -o vlan2001 -j SNAT --to-source x.x.x.x-x.x.x.x --persistent -A POSTROUTING -o vlan2000 -j SNAT --to-source x.x.x.x-x.x.x.x --persistent -A dnat_post -d 172.19.0.1/32 -p udp -m multiport --dports 80,443 -j SNAT --to-source 172.19.0.6 -A dnat_post -d 172.19.0.1/32 -p tcp -m multiport --dports 80,443 -j SNAT --to-source 172.19.0.6 -A dnat_post -d 10.194.123.7/32 -p tcp -m multiport --dports 6036,6037,6038,6039 -j SNAT --to-source 172.19.0.6 -A dnat_post -d 10.194.126.9/32 -p tcp -m multiport --dports 50001,50002 -j SNAT --to-source 172.19.0.6 -A dnat_post -d 10.193.0.10/32 -p tcp -m multiport --dports 50004,50005 -j SNAT --to-source 172.19.0.6 -A dnat_post -d 10.193.0.166/32 -p tcp -m multiport --dports 50006,50007 -j SNAT --to-source 172.19.0.6 -A dnat_post -d 10.193.0.166/32 -p udp -m multiport --dports 50006,50007 -j SNAT --to-source 172.19.0.6 -A dnat_post -d 10.193.0.156/32 -p tcp -m multiport --dports 50008,50029 -j SNAT --to-source 172.19.0.6 -A dnat_post -d 10.193.0.41/32 -p tcp -m multiport --dports 50009,50010,50012 -j SNAT --to-source 172.19.0.6 -A dnat_post -d 10.193.0.41/32 -p tcp -m multiport --dports 80 -j SNAT --to-source 172.19.0.6 -A dnat_post -d 10.193.0.180/32 -p tcp -m multiport --dports 50014,50015,50050 -j SNAT --to-source 172.19.0.6 -A dnat_post -d 10.193.0.130/32 -p tcp -m multiport --dports 50016,50017,50025 -j SNAT --to-source 172.19.0.6 -A dnat_post -d 10.193.0.181/32 -p tcp -m multiport --dports 50027,50028 -j SNAT --to-source 172.19.0.6 -A dnat_post -d 10.194.126.7/32 -p tcp -m multiport --dports 50029,50030,50031,50032 -j SNAT --to-source 172.19.0.6 -A dnat_post -d 10.193.0.216/32 -p tcp -m multiport --dports 50033,50034,50035,50036 -j SNAT --to-source 172.19.0.6 -A dnat_post -d 10.193.1.223/32 -p tcp -m multiport --dports 50037,50038 -j SNAT --to-source 172.19.0.6 -A dnat_post -d 10.193.1.253/32 -p tcp -m multiport --dports 50039,50040,50041,50042,50043,50044,50045,50046,50047,50048,50049 -j SNAT --to-source 172.19.0.6 -A dnat_post -d 10.193.2.8/32 -p tcp -m multiport --dports 50050,50051,50054 -j SNAT --to-source 172.19.0.6 -A dnat_post -d 10.193.2.9/32 -p tcp -m multiport --dports 50052,50053 -j SNAT --to-source 172.19.0.6 -A dnat_post -d 10.193.1.2/32 -p tcp -m multiport --dports 50055,50056,50057,50058,50059,50060,50061,50062,50063,50064,50065 -j SNAT --to-source 172.19.0.6 -A dnat_post -d 172.20.0.100/32 -p tcp -m multiport --dports 80 -j SNAT --to-source 172.19.0.6 -A dnat_post -d 172.20.0.101/32 -p tcp -m multiport --dports 80 -j SNAT --to-source 172.19.0.6 -A dnat_post -d 172.20.0.102/32 -p tcp -m multiport --dports 80 -j SNAT --to-source 172.19.0.6 -A dnat_post -d 172.20.0.103/32 -p tcp -m multiport --dports 80 -j SNAT --to-source 172.19.0.6 -A dnat_post -d 172.20.0.104/32 -p tcp -m multiport --dports 80 -j SNAT --to-source 172.19.0.6 -A dnat_post -d 10.193.0.244/32 -p tcp -m multiport --dports 60001,60002,60003 -j SNAT --to-source 172.19.0.6 -A dnat_post -d 10.194.130.5/32 -p tcp -m multiport --dports 50100:50200 -j SNAT --to-source 172.19.0.6 -A dnat_post -d 10.194.129.17/32 -p tcp -m multiport --dports 50203:50213 -j SNAT --to-source 172.19.0.6 -A dnat_post -d 10.194.101.97/32 -p tcp -m multiport --dports 25565,25567,25568,30000,30001,50069:50099,4254:4258 -j SNAT --to-source 172.19.0.6 -A dnat_post -d 10.194.101.97/32 -p udp -m multiport --dports 25565,25567,25568,30000,30001,50069:50099,4254:4258 -j SNAT --to-source 172.19.0.6 -A dnat_pre -p tcp -m multiport --dports 80,443 -j DNAT --to-destination 172.19.0.1 -A dnat_pre -p udp -m multiport --dports 80,443 -j DNAT --to-destination 172.19.0.1 -A dnat_pre -p tcp -m multiport --dports 6036,6037,6038,6039 -j DNAT --to-destination 10.194.123.7 -A dnat_pre -p tcp -m multiport --dports 50001,50002 -j DNAT --to-destination 10.194.126.9 -A dnat_pre -p tcp -m multiport --dports 50004,50005 -j DNAT --to-destination 10.193.0.10 -A dnat_pre -p tcp -m multiport --dports 50006,50007 -j DNAT --to-destination 10.193.0.166 -A dnat_pre -p udp -m multiport --dports 50006,50007 -j DNAT --to-destination 10.193.0.166 -A dnat_pre -p tcp -m multiport --dports 50008,50029 -j DNAT --to-destination 10.193.0.156 -A dnat_pre -p tcp -m multiport --dports 50009,50010,50012 -j DNAT --to-destination 10.193.0.41 -A dnat_pre -p tcp -m multiport --dports 50013 -j DNAT --to-destination 10.193.0.41:80 -A dnat_pre -p tcp -m multiport --dports 50014,50015,50050 -j DNAT --to-destination 10.193.0.180 -A dnat_pre -p tcp -m multiport --dports 50016,50017,50025 -j DNAT --to-destination 10.193.0.130 -A dnat_pre -p tcp -m multiport --dports 50027,50028 -j DNAT --to-destination 10.193.0.181 -A dnat_pre -p tcp -m multiport --dports 50029,50030,50031,50032 -j DNAT --to-destination 10.194.126.7 -A dnat_pre -p tcp -m multiport --dports 50033,50034,50035,50036 -j DNAT --to-destination 10.193.0.216 -A dnat_pre -p tcp -m multiport --dports 50037,50038 -j DNAT --to-destination 10.193.1.223 -A dnat_pre -p tcp -m multiport --dports 50039,50040,50041,50042,50043,50044,50045,50046,50047,50048,50049 -j DNAT --to-destination 10.193.1.253 -A dnat_pre -p tcp -m multiport --dports 50050,50051,50054 -j DNAT --to-destination 10.193.2.8 -A dnat_pre -p tcp -m multiport --dports 50052,50053 -j DNAT --to-destination 10.193.2.9 -A dnat_pre -p tcp -m multiport --dports 50055,50056,50057,50058,50059,50060,50061,50062,50063,50064,50065 -j DNAT --to-destination 10.193.1.2 -A dnat_pre -p tcp -m multiport --dports 50066 -j DNAT --to-destination 172.20.0.101:80 -A dnat_pre -p tcp -m multiport --dports 50067 -j DNAT --to-destination 172.20.0.102:80 -A dnat_pre -p tcp -m multiport --dports 50068 -j DNAT --to-destination 172.20.0.103:80 -A dnat_pre -p tcp -m multiport --dports 50201 -j DNAT --to-destination 172.20.0.104:80 -A dnat_pre -p tcp -m multiport --dports 50202 -j DNAT --to-destination 172.20.0.100:80 -A dnat_pre -p tcp -m multiport --dports 60001,60002,60003 -j DNAT --to-destination 10.193.0.244 -A dnat_pre -p tcp -m multiport --dports 50100:50200 -j DNAT --to-destination 10.194.130.5 -A dnat_pre -p tcp -m multiport --dports 50203:50213 -j DNAT --to-destination 10.194.129.17 -A dnat_pre -p tcp -m multiport --dports 25565,25567,25568,30000,30001,50069:50099,4254:4258 -j DNAT --to-destination 10.194.101.97 -A dnat_pre -p udp -m multiport --dports 25565,25567,25568,30000,30001,50069:50099,4254:4258 -j DNAT --to-destination 10.194.101.97 COMMIT # Completed on Sun Oct 22 19:26:25 2017 # Generated by iptables-save v1.6.0 on Sun Oct 22 19:26:25 2017 *filter :INPUT DROP [17693988:1151289130] :FORWARD ACCEPT [6210831585:4372167186654] :OUTPUT ACCEPT [3012059:185032231] :input_check - [0:0] :input_new - [0:0] -A INPUT -m conntrack --ctstate INVALID -j DROP -A INPUT -m conntrack --ctstate RELATED,ESTABLISHED -j ACCEPT -A INPUT -i lo -j ACCEPT -A INPUT -m conntrack --ctstate NEW -j input_new -A FORWARD -p tcp -m set --match-set blacklist dst -j REJECT --reject-with tcp-reset -A FORWARD -m set --match-set blacklist dst -j REJECT --reject-with icmp-port-unreachable -A input_check -m recent --update --seconds 600 --hitcount 3 --name DEFAULT --mask 255.255.255.255 --rsource -j LOG --log-prefix "iptables INPUT bruteforce: " -A input_check -m recent --update --seconds 600 --hitcount 3 --name DEFAULT --mask 255.255.255.255 --rsource -j DROP -A input_check -m recent --set --name DEFAULT --mask 255.255.255.255 --rsource -j ACCEPT -A input_new -p tcp -m tcp --dport 62222 -j input_check -A input_new -p icmp -m icmp --icmp-type 8 -j ACCEPT -A input_new -m set --match-set input_src src -j ACCEPT COMMIT # Completed on Sun Oct 22 19:26:25 2017 # Generated by iptables-save v1.6.0 on Sun Oct 22 19:26:25 2017 *mangle :PREROUTING ACCEPT [6281246694:4399573830530] :INPUT ACCEPT [18372969:1224294865] :FORWARD ACCEPT [6252457074:4397551045317] :OUTPUT ACCEPT [3026359:186311938] :POSTROUTING ACCEPT [6253156115:4397605844275] :balance - [0:0] :new_conn - [0:0] -A PREROUTING -m conntrack --ctstate NEW -j new_conn -A PREROUTING -j CONNMARK --restore-mark --nfmask 0xffffffff --ctmask 0xffffffff -A FORWARD -p tcp -m tcp --tcp-flags SYN,RST SYN -j TCPMSS --clamp-mss-to-pmtu -A balance -m statistic --mode random --probability 0.50000000000 -j SET --add-set vlan2000 src -A balance -m set --match-set uplink_list src -j RETURN -A balance -m statistic --mode random --probability 1.00000000000 -j SET --add-set vlan2001 src -A new_conn -m set --match-set ip_pools src -m set ! --match-set uplink_list src -j balance -A new_conn -m set --match-set vlan2000 src -j CONNMARK --set-xmark 0x1/0xffffffff -A new_conn -m set --match-set vlan2001 src -j CONNMARK --set-xmark 0x2/0xffffffff -A new_conn -m set --match-set vlan2000 src -j SET --add-set vlan2000 src --exist -A new_conn -m set --match-set vlan2001 src -j SET --add-set vlan2001 src --exist COMMIT # Completed on Sun Oct 22 19:26:25 2017 Еще раз спасибо за помощь. UPD: и вот спустя 55 мин. его попустило.
-
Сложно вам что-то посоветовать, потому что больше данных в теме не стало. Крутить там можно много чего с разными результатами. ITR можно увидеть в логах ядра при инициализации драйвера, но если вы не трогали настройки, то там 1 по-умолчанию. Конкретное значение количества прерываний выбранные драйвером в конкретный момент посмотреть нельзя, только через всякие dstat/vmstat высчитывать. Как вы заметили по теме, я, например, рекомендую прибивать статические значения, если настройки драйвера по-умолчанию не работают. Мне это помогло справиться с проблемой. Но является ли это решением в вашем случае сказать сложно. То что видно в кернел.лог kernel: [319611.994725] igb 0000:01:00.0 enp1s0f0: igb: enp1s0f0 NIC Link is Up 1000 Mbps Full Duplex, Flow Control: RX
-
Как сейчас с ifAlias ? У меня почему то пусто на дебиан под snmpd. IF-MIB::ifAlias.1 = STRING: IF-MIB::ifAlias.2 = STRING: IF-MIB::ifAlias.3 = STRING: IF-MIB::ifAlias.4 = STRING: Хотя алиас присутствует. 3: vlan10@eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default qlen 1000 link/ether 44:87:fc:52:4f:3b brd ff:ff:ff:ff:ff:ff alias lan
-
# lscpu Architecture: x86_64 CPU op-mode(s): 32-bit, 64-bit Byte Order: Little Endian CPU(s): 2 On-line CPU(s) list: 0,1 Thread(s) per core: 1 Core(s) per socket: 2 Socket(s): 1 NUMA node(s): 1 Vendor ID: GenuineIntel CPU family: 6 Model: 158 Model name: Intel(R) Celeron(R) CPU G3930 @ 2.90GHz Stepping: 9 CPU MHz: 799.871 CPU max MHz: 2900,0000 CPU min MHz: 800,0000 BogoMIPS: 5808.00 Virtualization: VT-x L1d cache: 32K L1i cache: 32K L2 cache: 256K L3 cache: 2048K NUMA node0 CPU(s): 0,1 Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc aperfmperf eagerfpu pni pclmulqdq dtes64 monitor ds_cpl vmx est tm2 ssse3 sdbg cx16 xtpr pdcm pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave rdrand lahf_lm abm 3dnowprefetch intel_pt tpr_shadow vnmi flexpriority ept vpid fsgsbase tsc_adjust smep erms invpcid mpx rdseed smap clflushopt xsaveopt xsavec xgetbv1 xsaves dtherm arat pln pts hwp hwp_notify hwp_act_window hwp_epp
-
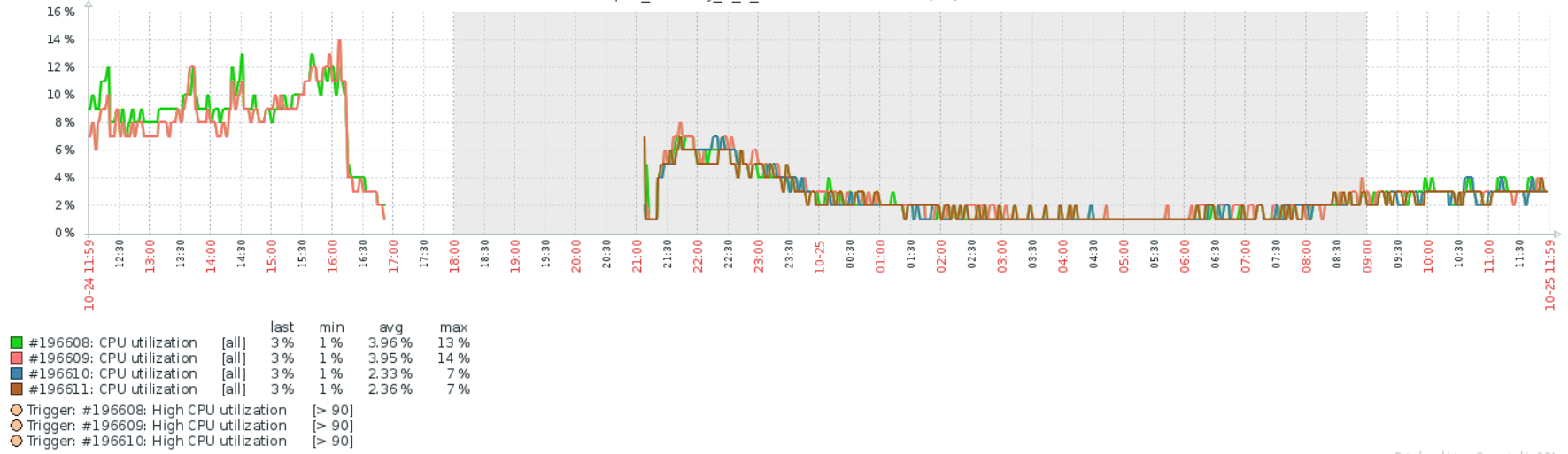
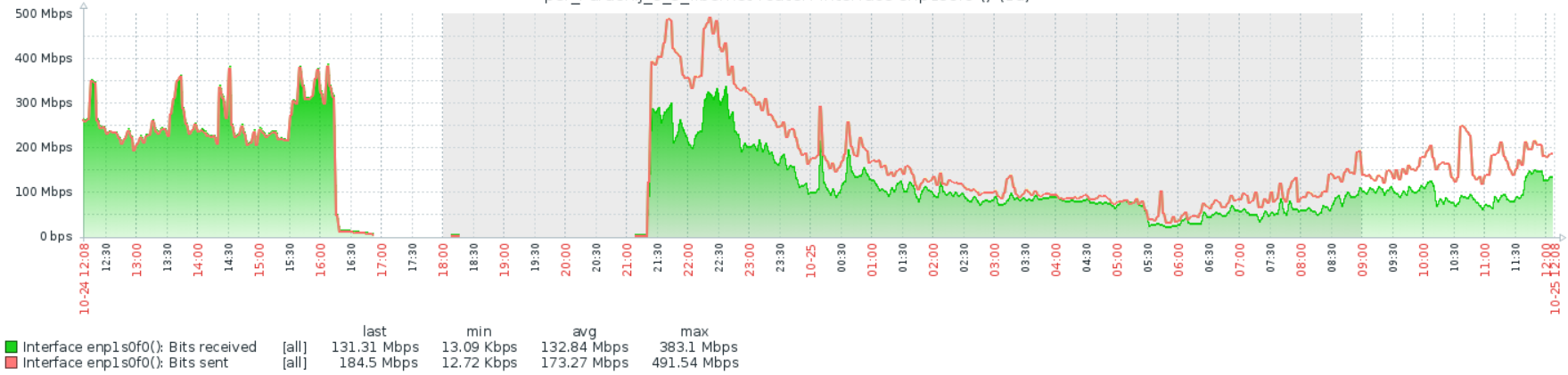
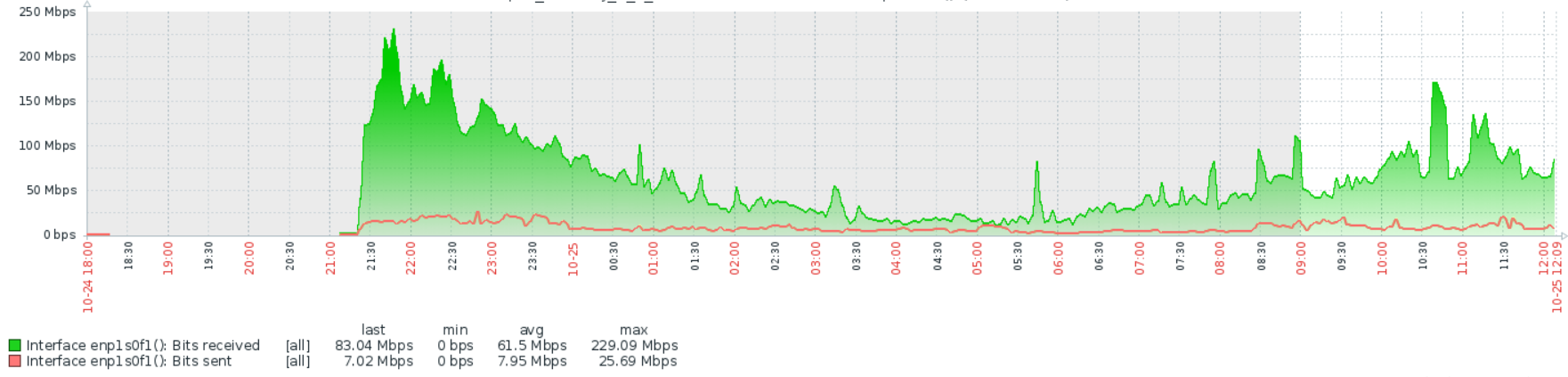
Ну там же вроде пакеты обрабатываются, которые от сетевой карты прилетели, сетевой стэк. У вас как бы не много выбора в любом случае: тюнить производительность стэка, но это не решит проблему в корне или дробить нагрузку на больше машин, вместо одной, что в общем-то единственный праведный путь с ядерным линуксовым натом. Я с Вами согласен насчет дробить на больше машин, но я думал это делать когда будет хотя бы 70% загрузки по ядрам. А у меня допустим вчера в чнн было 600мбит и 120кппс и загрузка цпу 35%. Моя проблема может говорить о какой-то недостаточности ресурсов? Вроде за всем слежу, но возможно что-то не понимаю.
-
Перечитал тему на наге, понял что не крутил только ITR. Вообще имеет смысл его трогать и как увидеть текущие значения его?
-
В момент проблемы ппс падает. Не успел физически добежать до сервера, чтобі запустить перф-топ.
-
А какая зависимость должна быть между pps и прерываниями? ППС рисуется, в пиках на данный момент около 130к.
-
Ну там же вроде пакеты обрабатываются, которые от сетевой карты прилетели, сетевой стэк. У вас как бы не много выбора в любом случае: тюнить производительность стэка, но это не решит проблему в корне или дробить нагрузку на больше машин, вместо одной, что в общем-то единственный праведный путь с ядерным линуксовым натом. Не могу понять просто, если слабое железо, тогда в час пик был бы затык, а так в час пик загрузка в районе 30%, эти всплески происходят рандомно и пока не объяснимо. Покритикуйте мой фаервол, не знаю вроде все оптимизировал что можно. # Generated by iptables-save v1.6.0 on Fri Oct 20 16:29:04 2017 *nat :PREROUTING ACCEPT [2365852486:172043329290] :INPUT ACCEPT [61985562:3870058168] :OUTPUT ACCEPT [447399:23734055] :POSTROUTING ACCEPT [14264173:570874256] :dnat_post - [0:0] :dnat_pre - [0:0] -A PREROUTING -d х.х.х.х -j dnat_pre -A OUTPUT -d х.х.х.х -j dnat_pre -A POSTROUTING -m set --match-set ip_pools src -j dnat_post -A POSTROUTING -o vlan2001 -j SNAT --to-source х.х.х.х-х.х.х.х --persistent -A POSTROUTING -o vlan2000 -j SNAT --to-source х.х.х.х-х.х.х.х --persistent -A dnat_post -d 172.19.0.1/32 -p udp -m multiport --dports 80,443 -j SNAT --to-source 172.19.0.6 -A dnat_post -d 172.19.0.1/32 -p tcp -m multiport --dports 80,443 -j SNAT --to-source 172.19.0.6 -A dnat_post -d 10.194.123.7/32 -p tcp -m multiport --dports 6036,6037,6038,6039 -j SNAT --to-source 172.19.0.6 -A dnat_post -d 10.194.126.9/32 -p tcp -m multiport --dports 50001,50002 -j SNAT --to-source 172.19.0.6 -A dnat_post -d 10.193.0.10/32 -p tcp -m multiport --dports 50004,50005 -j SNAT --to-source 172.19.0.6 -A dnat_post -d 10.193.0.166/32 -p tcp -m multiport --dports 50006,50007 -j SNAT --to-source 172.19.0.6 -A dnat_post -d 10.193.0.166/32 -p udp -m multiport --dports 50006,50007 -j SNAT --to-source 172.19.0.6 -A dnat_post -d 10.193.0.156/32 -p tcp -m multiport --dports 50008,50029 -j SNAT --to-source 172.19.0.6 -A dnat_post -d 10.193.0.41/32 -p tcp -m multiport --dports 50009,50010,50012 -j SNAT --to-source 172.19.0.6 -A dnat_post -d 10.193.0.41/32 -p tcp -m multiport --dports 80 -j SNAT --to-source 172.19.0.6 -A dnat_post -d 10.193.0.180/32 -p tcp -m multiport --dports 50014,50015,50050 -j SNAT --to-source 172.19.0.6 -A dnat_post -d 10.193.0.130/32 -p tcp -m multiport --dports 50016,50017,50025 -j SNAT --to-source 172.19.0.6 -A dnat_post -d 10.193.0.181/32 -p tcp -m multiport --dports 50027,50028 -j SNAT --to-source 172.19.0.6 -A dnat_post -d 10.194.126.7/32 -p tcp -m multiport --dports 50029,50030,50031,50032 -j SNAT --to-source 172.19.0.6 -A dnat_post -d 10.193.0.216/32 -p tcp -m multiport --dports 50033,50034,50035,50036 -j SNAT --to-source 172.19.0.6 -A dnat_post -d 10.193.1.223/32 -p tcp -m multiport --dports 50037,50038 -j SNAT --to-source 172.19.0.6 -A dnat_post -d 10.193.1.253/32 -p tcp -m multiport --dports 50039,50040,50041,50042,50043,50044,50045,50046,50047,50048,50049 -j SNAT --to-source 172.19.0.6 -A dnat_post -d 10.193.2.8/32 -p tcp -m multiport --dports 50050,50051,50054 -j SNAT --to-source 172.19.0.6 -A dnat_post -d 10.193.2.9/32 -p tcp -m multiport --dports 50052,50053 -j SNAT --to-source 172.19.0.6 -A dnat_post -d 10.193.1.2/32 -p tcp -m multiport --dports 50055,50056,50057,50058,50059,50060,50061,50062,50063,50064,50065 -j SNAT --to-source 172.19.0.6 -A dnat_post -d 172.20.0.100/32 -p tcp -m multiport --dports 80 -j SNAT --to-source 172.19.0.6 -A dnat_post -d 172.20.0.101/32 -p tcp -m multiport --dports 80 -j SNAT --to-source 172.19.0.6 -A dnat_post -d 172.20.0.102/32 -p tcp -m multiport --dports 80 -j SNAT --to-source 172.19.0.6 -A dnat_post -d 172.20.0.103/32 -p tcp -m multiport --dports 80 -j SNAT --to-source 172.19.0.6 -A dnat_post -d 172.20.0.104/32 -p tcp -m multiport --dports 80 -j SNAT --to-source 172.19.0.6 -A dnat_post -d 10.193.0.244/32 -p tcp -m multiport --dports 60001,60002,60003 -j SNAT --to-source 172.19.0.6 -A dnat_post -d 10.194.130.5/32 -p tcp -m multiport --dports 50100:50200 -j SNAT --to-source 172.19.0.6 -A dnat_post -d 10.194.129.17/32 -p tcp -m multiport --dports 50203:50213 -j SNAT --to-source 172.19.0.6 -A dnat_post -d 10.194.101.97/32 -p tcp -m multiport --dports 25565,25567,25568,30000,30001,50069:50099,4254:4258 -j SNAT --to-source 172.19.0.6 -A dnat_post -d 10.194.101.97/32 -p udp -m multiport --dports 25565,25567,25568,30000,30001,50069:50099,4254:4258 -j SNAT --to-source 172.19.0.6 -A dnat_pre -p tcp -m multiport --dports 80,443 -j DNAT --to-destination 172.19.0.1 -A dnat_pre -p udp -m multiport --dports 80,443 -j DNAT --to-destination 172.19.0.1 -A dnat_pre -p tcp -m multiport --dports 6036,6037,6038,6039 -j DNAT --to-destination 10.194.123.7 -A dnat_pre -p tcp -m multiport --dports 50001,50002 -j DNAT --to-destination 10.194.126.9 -A dnat_pre -p tcp -m multiport --dports 50004,50005 -j DNAT --to-destination 10.193.0.10 -A dnat_pre -p tcp -m multiport --dports 50006,50007 -j DNAT --to-destination 10.193.0.166 -A dnat_pre -p udp -m multiport --dports 50006,50007 -j DNAT --to-destination 10.193.0.166 -A dnat_pre -p tcp -m multiport --dports 50008,50029 -j DNAT --to-destination 10.193.0.156 -A dnat_pre -p tcp -m multiport --dports 50009,50010,50012 -j DNAT --to-destination 10.193.0.41 -A dnat_pre -p tcp -m multiport --dports 50013 -j DNAT --to-destination 10.193.0.41:80 -A dnat_pre -p tcp -m multiport --dports 50014,50015,50050 -j DNAT --to-destination 10.193.0.180 -A dnat_pre -p tcp -m multiport --dports 50016,50017,50025 -j DNAT --to-destination 10.193.0.130 -A dnat_pre -p tcp -m multiport --dports 50027,50028 -j DNAT --to-destination 10.193.0.181 -A dnat_pre -p tcp -m multiport --dports 50029,50030,50031,50032 -j DNAT --to-destination 10.194.126.7 -A dnat_pre -p tcp -m multiport --dports 50033,50034,50035,50036 -j DNAT --to-destination 10.193.0.216 -A dnat_pre -p tcp -m multiport --dports 50037,50038 -j DNAT --to-destination 10.193.1.223 -A dnat_pre -p tcp -m multiport --dports 50039,50040,50041,50042,50043,50044,50045,50046,50047,50048,50049 -j DNAT --to-destination 10.193.1.253 -A dnat_pre -p tcp -m multiport --dports 50050,50051,50054 -j DNAT --to-destination 10.193.2.8 -A dnat_pre -p tcp -m multiport --dports 50052,50053 -j DNAT --to-destination 10.193.2.9 -A dnat_pre -p tcp -m multiport --dports 50055,50056,50057,50058,50059,50060,50061,50062,50063,50064,50065 -j DNAT --to-destination 10.193.1.2 -A dnat_pre -p tcp -m multiport --dports 50066 -j DNAT --to-destination 172.20.0.101:80 -A dnat_pre -p tcp -m multiport --dports 50067 -j DNAT --to-destination 172.20.0.102:80 -A dnat_pre -p tcp -m multiport --dports 50068 -j DNAT --to-destination 172.20.0.103:80 -A dnat_pre -p tcp -m multiport --dports 50201 -j DNAT --to-destination 172.20.0.104:80 -A dnat_pre -p tcp -m multiport --dports 50202 -j DNAT --to-destination 172.20.0.100:80 -A dnat_pre -p tcp -m multiport --dports 60001,60002,60003 -j DNAT --to-destination 10.193.0.244 -A dnat_pre -p tcp -m multiport --dports 50100:50200 -j DNAT --to-destination 10.194.130.5 -A dnat_pre -p tcp -m multiport --dports 50203:50213 -j DNAT --to-destination 10.194.129.17 -A dnat_pre -p tcp -m multiport --dports 25565,25567,25568,30000,30001,50069:50099,4254:4258 -j DNAT --to-destination 10.194.101.97 -A dnat_pre -p udp -m multiport --dports 25565,25567,25568,30000,30001,50069:50099,4254:4258 -j DNAT --to-destination 10.194.101.97 COMMIT # Completed on Fri Oct 20 16:29:04 2017 # Generated by iptables-save v1.6.0 on Fri Oct 20 16:29:04 2017 *filter :INPUT DROP [115192:7448489] :FORWARD ACCEPT [61422018:48339151629] :OUTPUT ACCEPT [120274:6595450] :input_check - [0:0] :input_new - [0:0] -A INPUT -m conntrack --ctstate INVALID -j DROP -A INPUT -m conntrack --ctstate RELATED,ESTABLISHED -j ACCEPT -A INPUT -i lo -j ACCEPT -A INPUT -m conntrack --ctstate NEW -j input_new -A INPUT -m set --match-set input_src src -j ACCEPT -A FORWARD -p tcp -m set --match-set blacklist dst -j REJECT --reject-with tcp-reset -A FORWARD -m set --match-set blacklist dst -j REJECT --reject-with icmp-port-unreachable -A input_check -m recent --update --seconds 600 --hitcount 3 --name DEFAULT --mask 255.255.255.255 --rsource -j LOG --log-prefix "iptables INPUT bruteforce: " -A input_check -m recent --update --seconds 600 --hitcount 3 --name DEFAULT --mask 255.255.255.255 --rsource -j DROP -A input_check -m recent --set --name DEFAULT --mask 255.255.255.255 --rsource -j ACCEPT -A input_new -p tcp -m tcp --dport 62222 -j input_check -A input_new -p icmp -m icmp --icmp-type 8 -j ACCEPT COMMIT # Completed on Fri Oct 20 16:29:04 2017 # Generated by iptables-save v1.6.0 on Fri Oct 20 16:29:04 2017 *mangle :PREROUTING ACCEPT [33477321686:22949699656297] :INPUT ACCEPT [111748565:8843192375] :FORWARD ACCEPT [33306284735:22936436463930] :OUTPUT ACCEPT [102902336:7146802469] :POSTROUTING ACCEPT [33395225642:22942815939212] :balance - [0:0] :incoming - [0:0] :marking - [0:0] :new_conn - [0:0] :vlan2000 - [0:0] :vlan2000_mark - [0:0] :vlan2001 - [0:0] :vlan2001_mark - [0:0] -A PREROUTING -m conntrack --ctstate NEW -j new_conn -A PREROUTING -j CONNMARK --restore-mark --nfmask 0xffffffff --ctmask 0xffffffff -A FORWARD -p tcp -m tcp --tcp-flags SYN,RST SYN -j TCPMSS --clamp-mss-to-pmtu -A balance -m statistic --mode random --probability 0.50000000000 -j vlan2000 -A balance -m statistic --mode random --probability 1.00000000000 -j vlan2001 -A incoming -i vlan2000 -j CONNMARK --set-xmark 0x1/0xffffffff -A incoming -i vlan2001 -j CONNMARK --set-xmark 0x2/0xffffffff -A marking -m set --match-set vlan2000 src -j vlan2000_mark -A marking -m set --match-set vlan2001 src -j vlan2001_mark -A new_conn -m set --match-set ip_pools src -m set ! --match-set uplink_list src -j balance -A new_conn -m set --match-set uplink_if src,src -m connmark --mark 0x0 -j incoming -A new_conn -m set --match-set uplink_list src -m connmark --mark 0x0 -j marking -A vlan2000 -m set --match-set uplink_list src -j RETURN -A vlan2000 -j SET --add-set vlan2000 src -A vlan2000_mark -j CONNMARK --set-xmark 0x1/0xffffffff -A vlan2000_mark -j SET --add-set vlan2000 src --exist -A vlan2001 -m set --match-set uplink_list src -j RETURN -A vlan2001 -j SET --add-set vlan2001 src -A vlan2001_mark -j CONNMARK --set-xmark 0x2/0xffffffff -A vlan2001_mark -j SET --add-set vlan2001 src --exist COMMIT # Completed on Fri Oct 20 16:29:04 2017
-
Спасибо за советы попробую отловить что-нибудь. 3 root 20 0 0 0 0 R 96,4 0,0 39:08.06 ksoftirqd/0 16 root 20 0 0 0 0 R 96,4 0,0 44:47.19 ksoftirqd/1 7 root 20 0 0 0 0 S 1,7 0,0 12:37.07 rcu_sched ksoftirqd. не могу понять что его грузит.
-
Ребята скажите а у всех пинги скачут до ОЛТ под нагрузкой на 3310с? Стоит один 3310с и второй b, c включен каскадом в b. До b пинг в норме, до с в среднем 100мс.
-
Где именно? На свиче куда включен сервер? В принципе везде управляемое оборудование откуда ей взяться?