Baneff
-
Всього повідомлень
971 -
Приєднався
-
Останній візит
-
Дней в лидерах
28
Тип контенту
Профили
Форум
Календарь
Все, що було написано Baneff
-
Где тут речь была о пакетном фильтре? Он и на фре паралелится. Речь была о шейпере. Шейпер в tc многопоточный? Не делайте вид, что не понимаете разницы. И да, проще посоветовать человеку перейти на ratelimit и это не потому, что человек этот тупой, а потому что другого решения проблемы просто нет, по крайней мере там в обсуждении его никто не предложил.
-
Смеялся. Пару месяцев назад на известном вражеском форуме обсуждалась тема "tc + centos 7 грузят процессор под 100%". Так вот, это вам ничего не напоминает? И главная рекомендация - перейдите на ipt_ratelimit и оно попустит. )))
-
И, кстати, tc ваш параллелится?
-
Возможно. Я человек старой закалки и меня учили, что должен быть шейпер и тогда юзеры довольны и не достают поддержку, ничего у них не дергается и не обрывается. Это как-то связано со скоростью по тарифному плану? Типа если скорость высокая, то шейпер не нужен? Лично я сомневаюсь, но могу ошибаться. Однако тогда у меня появляется вопрос о корректности многочисленных сравнений фри и линукса. Это мы значит сравниваем систему с полноценным шейпингом (действительно даёт нагрузку на систему) с системой с тупым полисингом (никакой нагрузки, любой копеечный свич умеет). Уважаемые линоксоводы и линуксолюбы, это как, справедливо? Давайте включайте тогда ваш tc с включеннім шейпингом и тогда будем сравнивать. Или давайте мы на фре включим полисинг вместо шейпинга и тогда сравним. Думаю результаты вряд ли тогда будут сильно отличаться ибо в обеих системах сетевой стек давно вылизан и там уже некуда что-то оптимизировать, ну по мелочам разве.
-
Ха, та кокой же это шейпер? Пакеты дропать много ума не надо, так и на фре можно без всяких там нагрузок. Шейпер под Дебиан есть? Ну хоть что-то близкое по функционалу к dummynet ?
-
А шейпер для IPoE под дебианом как реализован? Имхо шейпинг - узкое место в софтовых брасах. Терминация, нат, файервол, птичка при наличии x520-DA2 на любой системе до 10 гиг прокачается юзерского трафика при современной средней длине пакета около 900 байт. Поскольку всё отлично паралелится, а процессоры многоядерные и память сейчас копейки стоят на вторичном рынке. У FreeBSD вижу единственное узкое место - лучший шейпер этой системы dummynet не параллелится и это заставляет искать не столько многоядерные системы, сколько системы с максимальным быстродействием на одно ядро. Конечно, при правильной настройке шейпера такой тазик работает, но это несколько напрягает, да. Узкое место - оно и есть узкое место. Интересно, что dummynet зачем-то портировали на линукс, я по крайней мере видел это в новостях. Поскольку я ни разу не специалист по линуксу, то мне интересно, как там реализован шейпинг, обеспечивает ли он хорошее качество нарезки при минимальной нагрузке на процессор и паралелится ли он там?. Я не оспариваю того факта, что линукс, возможно, резвее чем FreeBSD на том-же железе, вполне может быть. Даже если так, то это всё равно не заставит меня переходить на другую ось ибо коней на переправе не меняют и таки главные постулаты админа по прежнему "работает - не трогай" и "лучшее - враг хорошего". Увы, такова жизнь.
-
Ну спорить не буду, у каждого свои ньюансы, всякое может быть.
-
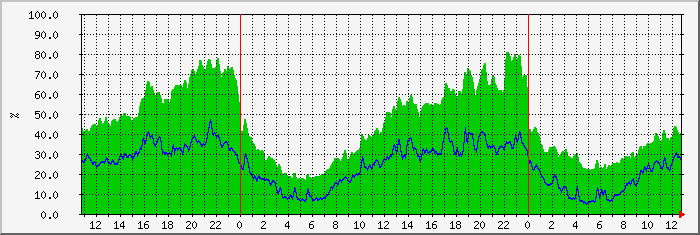
Ну вы пошли в обход вместо того, чтобы разобраться в чём дело. Я тоже из своего опыта: за много лет никогда не возникало необходимости включать pf и нагрузка как бы давно не 600кбит/с. Большую роль играет правильность составления правил ipfw. Всё должно быть логично, всё что можно - паковать в таблицы, минимум правил. А я встречал конфигурации, где были тысячи правил, так чего ж удивляться. Вот, например ниже график загрузки процессора (зелёный) и отдельно dummynet (синий) на довольно таки нагруженной машинке на боевом дежурстве. Никаких костылей, всё штатно.

-
И ещё, на всякий случай напомню, что dummynet - это только одна из частей ipfw, которая занимается только шейпингом, всё остальное в ipfw прекрасно параллелится.
-
От же ж. Ну почему он ущербный? Однопоточность его - это единственный недостаток, который работе не мешает. Он и в один поток шейпит прекрасно. Чем шейпить-то будете?
-
LACP host FreeBSD - switch 3120-24SC
тема ответил в WideAreaNetwork пользователя Baneff в Для тих, хто в пелюшках ще
А зачем такой венигрет? Зачем сразу и ipfw и pf ? Там у вас наверное еще много сюрпризов, по одному выдаёте нагора? -
LACP host FreeBSD - switch 3120-24SC
тема ответил в WideAreaNetwork пользователя Baneff в Для тих, хто в пелюшках ще
Вы там в соседней теме интересуетесь как посмотреть сколько pf кушает. У вас там ещё и pf есть? Извините за любопытство. -
LACP host FreeBSD - switch 3120-24SC
тема ответил в WideAreaNetwork пользователя Baneff в Для тих, хто в пелюшках ще
Уж много раз твердили миру... Лучшая система - это та, которую лучше всего знает ваш админ. Да хоть бы и Микротик, тоже есть специалисты, которые собаку на нём съели. Ну нравится им и всё, чего уж тут. Но что интересно, обычно именно приверженцы линуха особо агрессивны в форумах. Вот например специалисты по Junos или IOS вообще обычно помалкивают, хотя им точно есть что сказать -
LACP host FreeBSD - switch 3120-24SC
тема ответил в WideAreaNetwork пользователя Baneff в Для тих, хто в пелюшках ще
О, линуксятники набежали ))) . Чего вы обижаетесь? Хорош ваш линух, хорош, зачем спорить? Но вам же сказали ясно, у человека FreeBSD, так уж сложилось, и эта тема не по линух и не про то, что круче. Иш как возбудились, услышав об однопоточном dummynet , но он хоть и однопоточный, но есть и работает прекрасно, вместе с быстрыми и удобными многопоточными ipfw и ядерным nat-ом. А по делу, то как работала фря, так и работает несмотря на крики и вопли "рок-н-ролл мёртв". Старый конь борозды не испортит. Я 20+ лет на фре и менять ничего не собираюсь, надеюсь доживу уже с ней. Если бы речь шла о выборе на данный момент для новой системы, то тут стоило бы конечно подумать, а смена оси на стоящей на боевом дежурстве системе - да ну нах, даже думать об этом страшно. -
LACP host FreeBSD - switch 3120-24SC
тема ответил в WideAreaNetwork пользователя Baneff в Для тих, хто в пелюшках ще
Ну во первых - да, в эру анлимов особого смысла следить за трафиком юзеров не вижу ни для себя ни для самих юзеров. Если им надо - пусть сами считают, есть чем, слава Богу. Ну если провайдер особо жадный, то да, можно отслеживать и отстреливать наиболее потребляющих. Некоторые так делают, но каналы сейчас дешёвые, я считаю проще забить и забыть ибо сам подсчёт, контроль и отстрел тоже денег и нервов стОит. Другое дело - если по какой-то причине требуется детализация и архивирование трафика. Тогда - да, проблема. Любой коллектор даст большую нагрузку. Во вторых, методы есть. Например при схеме vlan-per-user, а это, имхо, самая правильная схема, можно снимать по snmp прямо с виланов. Или, например, если используется dummynet, то там тоже все нужные счётчики доступны и их можно периодически снимать скриптом и передавать куда надо. Ну это так, навскидку. Наверное и другие методы есть. -
LACP host FreeBSD - switch 3120-24SC
тема ответил в WideAreaNetwork пользователя Baneff в Для тих, хто в пелюшках ще
Да, это тоже проходили, конечно убрать ipcad . Надо было сразу огласить весь список. Лично я не против варианта "всё в одном", но некоторые вещи таки не стОит. А оно надо вообще, траффик мониторить? Кроме того есть и другие методы. -
LACP host FreeBSD - switch 3120-24SC
тема ответил в WideAreaNetwork пользователя Baneff в Для тих, хто в пелюшках ще
Ещё добавлю по поводу измерения нагрузки на ядра и процессы. Да, есть штатный top и в портах есть atop удобный и логи пишет. Есть в портах ещё какие-то утильки подобные. Но в своё время писали в форумах, что они неправильно показывают загрузку. Не знаю правильно или неправильно, сравнивать лень было, но была поставлена задача нарисовать с помощью системы mrtg (есть в портах) точно правильный график общей средней загрузки по всем ядрам и процессам и отдельно, как самый критичный, график загрузки dummynet. Оказалось, что самая первичная и самая точная информация о загрузке выдается в системных переменных kern.cp_time и поядерно kern.cp_times . Смотреть значения можно естественно с помощью sysctl и дальше обработка с помощью скрипта и передача данных в mrtg . Там данные по загрузке процессора в неких попугаях или тиках, неважно, но результат после вычислений выходит правильный. Если кого-то интересуют детали реализации, то могу попробовать поискать в архивах и сам скрипт и настройки mrtg . Этот же скрипт вычислял и загрузку dummynet с помощью утилит procstat и ps . -
LACP host FreeBSD - switch 3120-24SC
тема ответил в WideAreaNetwork пользователя Baneff в Для тих, хто в пелюшках ще
Отвечу тут на обращение в личку, может ещё кому пригодится. По поводу привязки процессов к ядрам. к ядрам. По состоянию на FreeBSD 11 . В 12 и 13 возможно что-то поменялось, не знаю, надо проверять. Наши эксперименты привели к отрицательному результату: попытка привязать dummynet или прерывания к ядрам ничего не улучшили, а может даже и ухудшили ситуацию. Система сама достаточно хорошо рапределяет нагрузку по ядрам в автомате, без ручного управления, поэтому в результате мы от привязки отказались. По поводу dummynet есть в нюансы. Во первых, надо учитывать, что dummynet всё ещё не научили на тот момент параллелиться, к сожалению в каждый момент одновременно работала только на одном ядре, хотя по ядрам скакала без проблем. Поэтому конфигурация с например четырьмя ядрами на 4-ГГц могла шейпить эффективнее, чем конфигурация с 16 ядрами на 2.4ГГц, вопрос был в скорости одного ядра. Все остальные процессы параллелились прекрасно, соответственно на многоядерной системе всё бегало бы резвее, но увы. Возможно сейчас уже исправили. Во-вторых. Много писали в форумах о том, что привязка dummynet ядру 0 резко снижает нагрузку. Так вот, это был такой баг, который к периоду 11-й и позже версий уже никакого отношения не имеет - исправили. Однако, если есть желание поэкспериментировать, то вот так это в 11-й делалось, нашёл я в своих записках вот такое: Привязать dummynet к определённому ядру CPU (пример): procstat -at | grep dummynet 0 100026 kernel dummynet 1 16 sleep - cpuset -t 100026 -l 0 Отвязать dummynet от определённых ядер и снова размазать по всем ядрам как было (для 8-core): cpuset -t 100026 -l 0-7 Привязывается dummynet к CPU0 одной командой: cpuset -l 0 -t `procstat -t 0 | awk '/dummynet/ {print $2}'` Прерывания можно привязать аналогично, хотя, как я уже сказал, нам это ничего не дало - отказались от этих попыток в результате. -
LACP host FreeBSD - switch 3120-24SC
тема ответил в WideAreaNetwork пользователя Baneff в Для тих, хто в пелюшках ще
Ну сам-то ipfw сильно систему не грузит, это надо специально постараться. Если там максимум несколько десятков правил с правильной логикой последовательности и с упаковкой данных в таблицы, то всё будет ок. Штатный ядерный NAT тоже не должен создавать большой нагрузки по идее. А вот штатный шейпер dummynet может легко пригрузить, да. Ну и потом систему грузит не так скорость, как кол-во пакетов в сек pps, котрые через систему пролетают? То есть если летит куча мелких пакетов, то это грузит больше. Но это ж азы, я так, на всякий случай. -
LACP host FreeBSD - switch 3120-24SC
тема ответил в WideAreaNetwork пользователя Baneff в Для тих, хто в пелюшках ще
Это фантастика какая-то. Ищите узкое место ибо 500мбит/с должно даже на одной встроенной карт работать, а не то что на лагге из 4-х интеловских карт. Смотрите загрузку процессора поядерно (top может показівать неверно!), смотрите есть ли потери пакетов, смотрите, какой именно процесс садит производительность, смотрите действительно ли приём и передача пакетов равномерно распределяются по физическим интерфейсам. Роутинг - это что? Есть BGP или просто статика? Нат, шейпер, файервол вполне могут садить всё. На чём сделано? Штатно, на ipfw? Ой, да тут столько вариантов может быть, что даже тяжело что-то посоветовать, вплоть до технической неисправности. Менять на лету можно те, которые меняются, которые в sysctl.conf. Те, которые в loader.conf - только через перезагрузку. Если на лету поменять нельзя - оно вам скажет, не переживайте. -
LACP host FreeBSD - switch 3120-24SC
тема ответил в WideAreaNetwork пользователя Baneff в Для тих, хто в пелюшках ще
Да, конечно, то что можно грузить модулями можете грузить. Это я по привычке. Хотя ipfw, если вы его используете, насколько я помню, в виде подгружаемого модуля до сих пор неполнофункциональный. Я до сих пор по убираю все лишнее из ядра и мира, ибо это опять стало актуально на виртуальных хостингах, там за память и ядра платить надо, а я жадный Да, системные переменные сильно изменены с 12-й версии и даже драйвера интеловских сетевух переименовали. igb уже там нету, пичалька. -
LACP host FreeBSD - switch 3120-24SC
тема ответил в WideAreaNetwork пользователя Baneff в Для тих, хто в пелюшках ще
Это хорошо, что 11-я, в 12-й уже всё поменялось. Так что наш старый конфиг должен по идее лечь нормально. Вот что откопал. Почему именно так - хз, я не помню уже. Возможно не до конца оптимально, но работало. Ниже только то, что касается сетевой подсистемы. > cat /sys/amd64/conf/AMD64 cpu HAMMER ident AMD64 options IPFIREWALL options IPFIREWALL_VERBOSE options IPFIREWALL_VERBOSE_LIMIT=10 options IPFIREWALL_DEFAULT_TO_ACCEPT options DUMMYNET options IPDIVERT options IPFIREWALL_NAT options LIBALIAS options HZ=1000 device lagg device netmap options TEKEN_UTF8 # UTF-8 output handling options TCP_RFC7413 # No Debugging support. nooptions INVARIANTS nooptions INVARIANT_SUPPORT nooptions WITNESS nooptions WITNESS_SKIPSPIN nooptions DEADLKRES ... [slipped] ... > > cat /boot/loader.conf machdep.hyperthreading_allowed=0 # https://calomel.org/network_performance.html net.inet.tcp.syncache.hashsize=1024 # (def=512) syncache hash size net.inet.tcp.syncache.bucketlimit=100 # (def=30) syncache bucket limit net.inet.tcp.tcbhashsize=4096 # (def=512) tcb hash size # Number of transmit descriptors per queue: hw.igb.txd=4096 # Number of receive descriptors per queue: hw.igb.rxd=4096 # MSIX should be the default for best performance, # but this allows it to be forced off for testing. # Enable MSI-X interrupts: # hw.igb.enable_msix: 1 hw.igb.enable_msix=1 # Tuneable Interrupt rate # Maximum interrupts per second: # hw.igb.max_interrupt_rate: 8000 hw.igb.max_interrupt_rate=32000 # Header split causes the packet header to be dma'd to a seperate mbuf from # the payload. This can have memory alignment benefits. But another plus is # that small packets often fit into the header and thus use no cluster. Its # a very workload dependent type feature. # Enable receive mbuf header split: # hw.igb.header_split: 0 hw.igb.header_split=1 # This will autoconfigure based on the number of CPUs if left at 0. # Number of queues to configure, 0 indicates autoconfigure: # hw.igb.num_queues: 0 hw.igb.num_queues=8 # How many packets rxeof tries to clean at a time. # Maximum number of received packets to process at a time, -1 means unlimited: # hw.igb.rx_process_limit: 100 hw.igb.rx_process_limit=1000 # Allow the administrator to limit the number of threads (CPUs) to use for # netisr. We don't check netisr_maxthreads before creating the thread for # CPU 0, so in practice we ignore values <= 1. This must be set at boot. # We will create at most one thread per CPU. # Use at most this many CPUs for netisr processing. #net.isr.maxthreads: 1 net.isr.maxthreads=7 # Bind netisr threads to CPUs. #net.isr.bindthreads: 0 net.isr.bindthreads=0 # Limit per-workstream mbuf queue limits s to at most net.isr.maxqlimit, # both for initial configuration and later modification using # netisr_setqlimit(). # Maximum netisr per-protocol, per-CPU queue depth. #net.isr.maxqlimit: 10240 net.isr.maxqlimit=16384 # The default per-workstream mbuf queue limit for protocols that don't # initialize the nh_qlimit field of their struct netisr_handler. If this is # set above netisr_maxqlimit, we truncate it to the maximum during boot. # Default netisr per-protocol, per-CPU queue limit if not set by protocol #net.isr.defaultqlimit: 256 net.isr.defaultqlimit=4096 # Attention! When combining interfaces in lagg, consider the influence of net.link.ifqmaxlen !!! # Outgoing interface queue length for lagg/bridge/tun/tap net.link.ifqmaxlen=10240 > cat /etc/sysctl.conf # AIM: Adaptive Interrupt Moderation which means that the interrupt rate # is varied over time based on the traffic for that interrupt vector # Enable adaptive interrupt moderation: # hw.igb.enable_aim: 1 hw.igb.enable_aim=1 # These sysctls were used in previous versions to control and export # dispatch policy state. Now, we provide read-only export via them so that # older netstat binaries work. At some point they can be garbage collected. #net.isr.direct #net.isr.direct_force # Three global direct dispatch policies are supported: #net.isr.dispatch=deferred (old net.isr.direct=0 net.isr.direct_force=0) # NETISR_DISPATCH_QUEUED: All work is deferred for a netisr, regardless of # context (may be overriden by protocols). #net.isr.dispatch=hybrid (old net.isr.direct=1 net.isr.direct_force=0) # NETISR_DISPATCH_HYBRID: If the executing context allows direct dispatch, # and we're running on the CPU the work would be performed on, then direct # dispatch it if it wouldn't violate ordering constraints on the workstream. #net.isr.dispatch=direct (old net.isr.direct=1 net.isr.direct_force=1) # NETISR_DISPATCH_DIRECT: If the executing context allows direct dispatch, # always direct dispatch. (The default.) #net.isr.dispatch=deferred net.isr.dispatch=direct # Фактически - размеры входящей и исходящей очередей. # При большой нагрузке в режиме маршрутизации есть смысл увеличивать. # Непоместившийся пакет выбрасывается. Это условно спасет при кратковременных # перегрузках (часть покетов пролетит с большой задержкой) но # совершенно не спасет при хроничеких. net.route.netisr_maxqlen=8192 # Обрабатывать входящие пакеты непосредственно в момент приема # (в т.ч. # прохождение ipfw на входе, до попадания в очередь netisr). # Есть смысл включать, если количество ядер меньше или равно количеству # сетевых карточек. Влияет на скорость ПРИЕМА пакетов. # Обработка пакета происходит прямо в обработчике прерывания. #net.inet.ip.fastforwarding=0 net.inet.ip.fastforwarding=1 # http://www.opennet.ru/docs/RUS/GigabitEthernet/ net.inet.ip.intr_queue_maxlen=10240 kern.ipc.maxsockbuf=8388608 net.inet.tcp.sendspace=3217968 net.inet.tcp.recvspace=3217968 #kern.ipc.nmbclusters=400000 kern.ipc.maxsockbuf=83886080 # http://download.intel.com/design/network/applnots/ap450.pdf # http://serverfault.com/questions/64356/freebsd-performance-tuning-sysctls-loader-conf-kernel # http://dadv.livejournal.com/139170.html # Доп. настройка сетевух. dev.igb.0.rx_processing_limit=4096 dev.igb.1.rx_processing_limit=4096 dev.igb.2.rx_processing_limit=4096 dev.igb.3.rx_processing_limit=4096 > -
LACP host FreeBSD - switch 3120-24SC
тема ответил в WideAreaNetwork пользователя Baneff в Для тих, хто в пелюшках ще
Чипы правильные. По поводу карт HP ничего сказать не могу, мы всегда ставили только родные Intel. Молитесь, чтобы стандартные драйвера подошли и чтобы HP ничего там не добавили полезного с их точки зрения, типа совместимости только с родными модулями. А так - всё по идее должно получиться. Далее. Какая версия фри? Конфиги зависят. -
LACP host FreeBSD - switch 3120-24SC
тема ответил в WideAreaNetwork пользователя Baneff в Для тих, хто в пелюшках ще
Ну тогда если будет правильная интеловская четырёхпортовка или правильная 10-гиговая карта, то на 8 ядер нагрузка должна быть более-менее равномерная. Есть ещё мнение, что двухпроцессорная система будет в качестве молотилки медленнее, чем даже если из неё просто вытянуть второй процессор. Типа за счёт накладных расходов по пересылке данных между банками памяти, которые таки привязаны к процессорам будут тормоза и один процессор справится лучше. Не могу ни подтвердить ни опровергнуть, сам лично не проверял, но встречал такое мнение неоднократно. Какую конкретно карту купили, тип, чип? Осторожно! Разница есть! От выбора алгоритма зависит насколько равномерно будут распределятся по интерфейсам пакеты, передаваемые свичём в сторону компа. При неправильном выборе может выйти, что трафик пойдёт по интерфейсам несимметрично или, например, даже весь пойдёт через один интерфейс. Это зависит от окружающей сети и типа передаваемого трафика. Я бы включал на всякий случай все возможные алгоритмы ибо хуже от этого не будет точно, а польза может быть. Я не силён в терминологии длинка, но подозреваю, что активный - это именно то, что первоначально и называлось LACP. Каждая пара портов с двух сторон посылает служебную информацию для контроля работоспособности линии. Так что если уж вы ставите на фре laggproto lacp , то и с другой стороны нужно ставить аналогичный режим, то есть скорее всего активный. Иначе, как вам уже тут писали, будут проблемы. Обсуждение и тут и на nag.ru біло вроде под названием "Софт роутер" или как-то так. А конфиги - ещё раз говорю, они железозависимые, скажите какую карту ставите, тип, чип? -
Тринити, youtv, Oll, Megogo, Divan - что выбрать ?
тема ответил в kvirtu пользователя Baneff в IPTV КТВ Кабельне телебачення
Я не Кеша, но всё же. А что тут можно сделать? Да, отсосать и прикупить канал пошире и новую оборудку. В первый раз что ли? Я прекрасно помню, как несколько лет назад вышла новая версия торента и трафик у провов резко возрос. Сколько было криков, стонов и даже попыток сорвать денег с авторов программы или заблокировать торрент вообще. И что? Отсосали, расширили и прикупили ибо провайдер всегда крайний и всё, что он может - это попытаться поднять цены, если конкурентная остановка позволяет, попытаться минимизировать расходы или продаться более крупному игроку. Так и сейчас. Можно взять партнёрку по ТВ или даже своё завести легальное или нелегальное, но кто может заставить юзера пользоваться именно местным телевидением собственного провайдера, если в интернете доступна куча других предложений? Пытаться блокировать внешних поставщиков телевидения - юзер проголосует ногами, уйдёт к конкуренту ибо провайдер по определению не имеет права что-либо блокировать или ограничивать. Так что весь этот вой бесполезен, смиритесь и доставайте кошельки, опять пришло время платить.- 107 ответов
-
- 2
-

-
- тринити youtv
- oll
- (та 2 ще)